We Benchmarked 3 Streaming ASR Providers Across 17 Hours of Audio. Here's What We Found.
By Whissle Research Team
Apr 10 2026
203
5471
4,915 samples. Four datasets. Clean speech, Indian-accented tech interviews, noisy soccer broadcasts, and Indian Supreme Court proceedings. A transparent, warts-and-all comparison of Whissle, Deepgram, and AssemblyAI.
Most ASR benchmarks test on LibriSpeech and call it a day. The provider with the lowest number on clean, studio-recorded audiobook narration wins, and everyone moves on.
But that's not the audio your application deals with.
Your audio has accents. Background noise. People talking fast, interrupting each other, mumbling through technical jargon. The question isn't "which ASR is best on clean speech?" -- it's "which ASR holds up when conditions get real?"
We set out to answer that question. We benchmarked three streaming ASR providers -- Whissle, Deepgram (Nova-2), and AssemblyAI (Universal Streaming) -- across four increasingly difficult datasets. We measured accuracy, latency, reliability, and real-time metadata capabilities. We ran all three providers in parallel on the same audio to ensure a fair comparison.
Here's everything we found.
How We Tested
All three providers were tested using real-time WebSocket streaming -- the exact protocol you'd use in production. Audio was streamed in 100ms chunks at 1x real-time speed, simulating a live microphone.
| Provider | Model | Streaming Endpoint |
|---|---|---|
| Whissle | Default (ONNX runtime) | wss://api.whissle.ai/asr/stream |
| Deepgram | Nova-2 | wss://api.deepgram.com/v1/listen |
| AssemblyAI | Universal Streaming | wss://streaming.assemblyai.com/v3/ws |
Fair comparison measures:
- All providers received identical audio (PCM int16, mono, 16kHz)
- All three ran concurrently on each sample -- same network conditions
- Text normalized before WER: lowercased, punctuation stripped, whitespace collapsed
- WER computed using the standard jiwer library
Key metrics:
| Metric | What It Measures |
|---|---|
| WER | Word Error Rate -- (Insertions + Deletions + Substitutions) / Reference Words |
| Corpus WER | Total errors / total reference words (avoids inflation from short utterances) |
| CER | Character Error Rate -- same formula at character level |
| Time to first segment | Milliseconds from audio stream start to first non-empty transcript |
| Failure rate | Percentage of samples that returned no usable transcript |
The Four Datasets
We deliberately chose datasets that span the difficulty spectrum -- one industry standard, three that represent real-world conditions.
Dataset 1: LibriSpeech test-clean
The industry baseline. Clean, clear, studio-quality audiobook narration.
| Property | Value |
|---|---|
| Source | openslr/librispeech_asr (HuggingFace) |
| Samples | 2,620 |
| Total audio | 5.4 hours (19,453 seconds) |
| Duration range | 1.3s -- 35.0s (median 5.8s) |
| Language | English (US) |
| Domain | Read audiobook speech |
| Conditions | Studio-quality, single speaker, no background noise |
| Duration Bucket | Samples | Percentage |
|---|---|---|
| Short (< 5s) | 1,089 | 41.6% |
| Medium (5--10s) | 917 | 35.0% |
| Long (> 10s) | 614 | 23.4% |
Why include it: It's the universal reference point. Every ASR paper reports LibriSpeech results, making it the baseline for cross-provider comparison.
Why it's not enough: No accents, no noise, no domain-specific vocabulary, no overlapping speakers. LibriSpeech performance doesn't predict real-world performance.
Dataset 2: EN-IN Tech Interviews
Indian-accented English in technical interview settings. Where clean-speech benchmarks break down.
| Property | Value |
|---|---|
| Source | WhissleAI/Meta_STT_EN-IN_Tech_Interviews (HuggingFace) |
| Samples | 1,204 |
| Total audio | 5.3 hours (18,969 seconds) |
| Duration range | 1.1s -- 20.0s (median 20.0s) |
| Language | English with Indian accents (EN-IN) |
| Domain | Technical interview conversations |
| Conditions | Variable quality, phone/video call audio, technical vocabulary |
| Duration Bucket | Samples | Percentage |
|---|---|---|
| Short (< 5s) | 95 | 7.9% |
| Medium (5--10s) | 140 | 11.6% |
| Long (> 10s) | 969 | 80.5% |
What makes it hard:
- Indian English accents. Retroflex consonants, vowel substitutions (/v/ for /w/), syllable-timed rhythm -- systematic phonetic differences from US/UK English.
- Technical vocabulary. Framework names, API terminology, algorithm discussions.
- Conversational patterns. Hesitations, false starts, filler words, incomplete sentences.
- Long utterances. 80% of samples exceed 10 seconds -- errors compound over longer audio.
- Variable recording quality. Phone/video call audio with varying mic quality and background noise.
Each sample includes ground-truth annotations for speaker age, gender, emotion, and intent -- stripped before WER calculation.
Dataset 3: Soccer Broadcast Commentary
Live match commentary with crowd noise, rapid speech, and proper nouns from a dozen nationalities. The hardest test.
| Property | Value |
|---|---|
| Source | Custom dataset from YouTube soccer match broadcasts |
| Samples | 327 |
| Total audio | 2.7 hours (9,810 seconds) |
| Segment duration | 30.0s each (uniform) |
| Language | English (UK) |
| Domain | Live soccer match commentary |
| Primary source | Manchester City v Manchester United -- 2024 Community Shield (326 segments) |
Rich ground-truth annotations embedded in reference text (stripped before WER):
| Annotation Type | Count | Examples |
|---|---|---|
| Player names | 379 | Fernandez, McAtee, Rashford |
| Team names | 139 | Manchester United, Arsenal |
| Game actions | 102 | shot, scored, corner, penalty |
| Referee decisions | 47 | penalty, offside |
| Competition names | 39 | Community Shield |
| Game timestamps | 36 | 90 minutes |
| Field positions | 30 | right hand side |
| Scores | 11 | 1-1, 7-6 |
| Ground-Truth Emotion | Samples | Ground-Truth Intent | Samples |
|---|---|---|---|
| Neutral | 202 (61.8%) | Analysis | 164 (50.2%) |
| Happy | 66 (20.2%) | Play-by-play | 114 (34.9%) |
| Sad | 59 (18.0%) | Statistic | 8 (2.4%) |
Speaker demographics: All male. 65% aged 60+, 35% aged 45--60.
What makes it the hardest:
- Constant background noise -- crowd chanting, whistles, stadium atmosphere
- Rapid speech -- commentators average ~150 WPM, spiking during action
- Proper noun density -- 379 player name mentions across 327 segments
- Multiple speakers -- two commentators frequently overlapping
- Domain jargon -- offside, set piece, penalty shootout
- 30-second segments -- long continuous audio with dense speech
- Broadcast processing -- dynamic range compression, crowd noise mixing
Dataset 4: Supreme Court of India Proceedings
Indian-accented legal English in a reverberant courtroom. Multiple speakers, heavy domain vocabulary, and challenging acoustics.
| Property | Value |
|---|---|
| Source | WhissleAI/supreme-court-india-meta-speech (HuggingFace) |
| Samples | 764 |
| Total audio | 4.2 hours (15,280 seconds) |
| Segment duration | 20.0s each (uniform) |
| Language | English with Indian accents (EN-IN) |
| Domain | Supreme Court oral arguments and judicial proceedings |
| Conditions | Courtroom acoustics, multiple speakers, legal terminology, reverberant environment |
What makes it hard:
- Indian English accents in formal legal speech. Judges, advocates, and amicus curiae speaking with varying regional accents -- phonetic patterns that trip up models trained primarily on US/UK English.
- Dense legal vocabulary. Case citations, Latin legal terms, constitutional provisions, statutory references -- highly specialized language that rarely appears in general training data.
- Reverberant courtroom acoustics. Large courtroom spaces produce echo and reverberation that degrades audio clarity.
- Multiple speakers. Judges, advocates, and interveners -- with frequent interruptions and cross-talk during oral arguments.
- Formal yet spontaneous speech. Legal arguments are partially prepared but delivered extemporaneously, with restarts, corrections, and hedging.
Results at a Glance
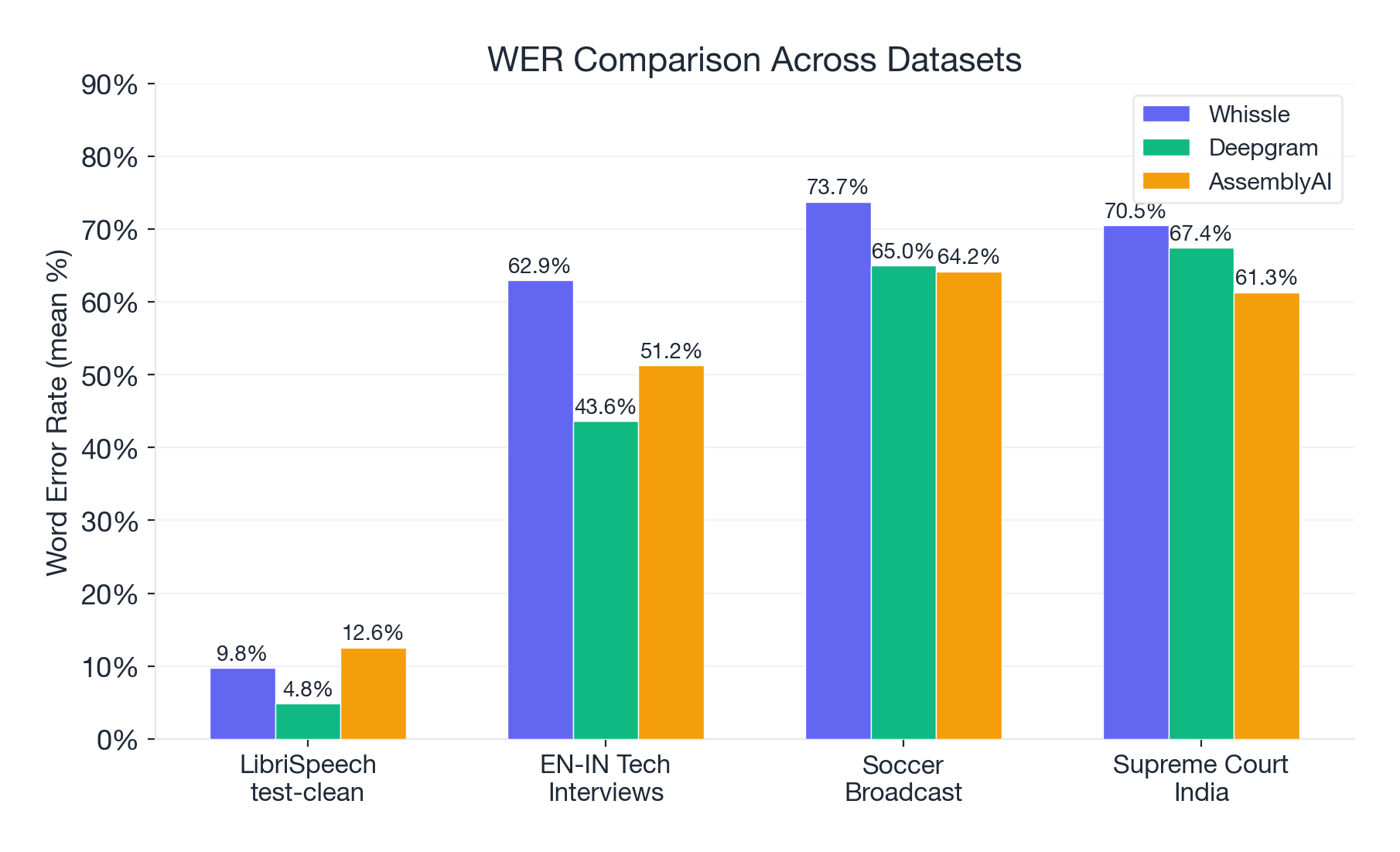
Accuracy: Deepgram Wins on WER
LibriSpeech test-clean (clean read speech):
| Metric | Whissle | Deepgram | AssemblyAI | Best |
|---|---|---|---|---|
| WER (mean) | 9.75% | 4.83% | 12.55% | DG |
| WER (median) | 6.25% | 0.00% | 6.67% | DG |
| Corpus WER | 8.24% | 4.16% | 11.11% | DG |
| CER (mean) | 4.30% | 2.05% | 11.74% | DG |
| Word confidence | 0.9494 | 0.9868 | 0.8679 | DG |
EN-IN Tech Interviews (accented conversational speech):
| Metric | Whissle | Deepgram | AssemblyAI | Best |
|---|---|---|---|---|
| WER (mean) | 62.94% | 43.62% | 51.25% | DG |
| WER (median) | 42.86% | 28.17% | 41.51% | DG |
| Corpus WER | 40.67% | 29.83% | 39.45% | DG |
| CER (mean) | 44.13% | 36.46% | 45.62% | DG |
Soccer Broadcast (noisy commentary):
| Metric | Whissle | Deepgram | AssemblyAI | Best |
|---|---|---|---|---|
| WER (mean) | 73.74% | 64.99% | 64.18% | AAI |
| WER (median) | 50.00% | 36.25% | 40.35% | DG |
| Corpus WER | 53.89% | 43.79% | 45.62% | DG |
| CER (mean) | 59.69% | 56.17% | 57.58% | DG |
Supreme Court India (legal proceedings):
| Metric | Whissle | Deepgram | AssemblyAI | Best |
|---|---|---|---|---|
| WER (mean) | 70.48% | 67.44% | 61.31% | AAI |
| WER (median) | 53.19% | 42.86% | 47.37% | DG |
| Corpus WER | 53.50% | 45.50% | 47.98% | DG |
| CER (mean) | 57.12% | 61.33% | 55.54% | AAI |
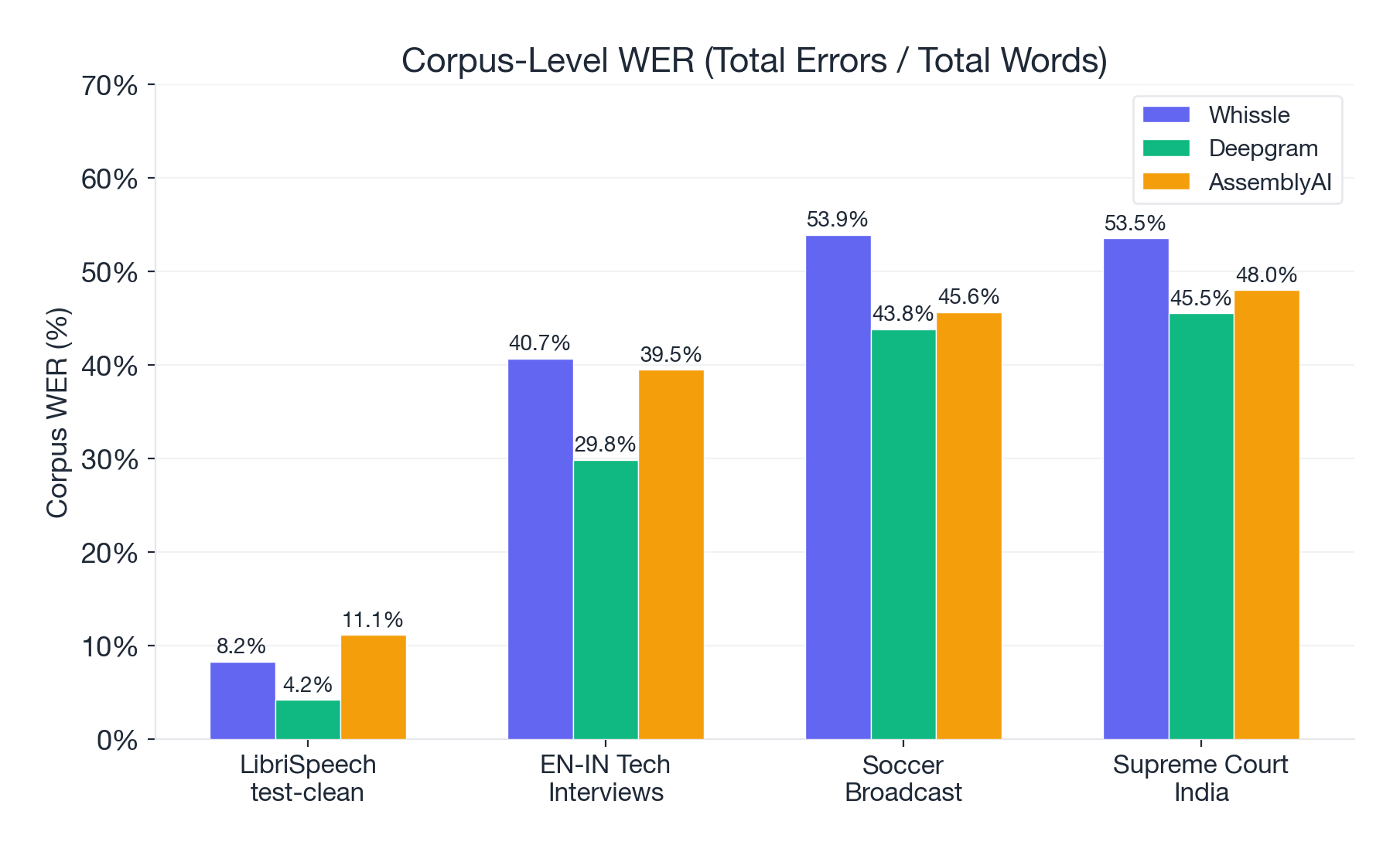
Deepgram's Nova-2 model delivers the best corpus-level accuracy across all four datasets. On clean speech it's excellent (4.16% corpus WER). But even Deepgram drops to 30--46% corpus WER on challenging audio -- a 7--11x degradation from its LibriSpeech numbers. The Supreme Court dataset is the hardest test: all three providers exceed 45% corpus WER, reflecting the combined difficulty of Indian accents, legal vocabulary, and courtroom acoustics.
Latency: Whissle Is 2--3x Faster to First Words
How quickly does the first transcript appear after audio starts streaming? This matters enormously for live captioning, real-time coaching, and conversational AI.
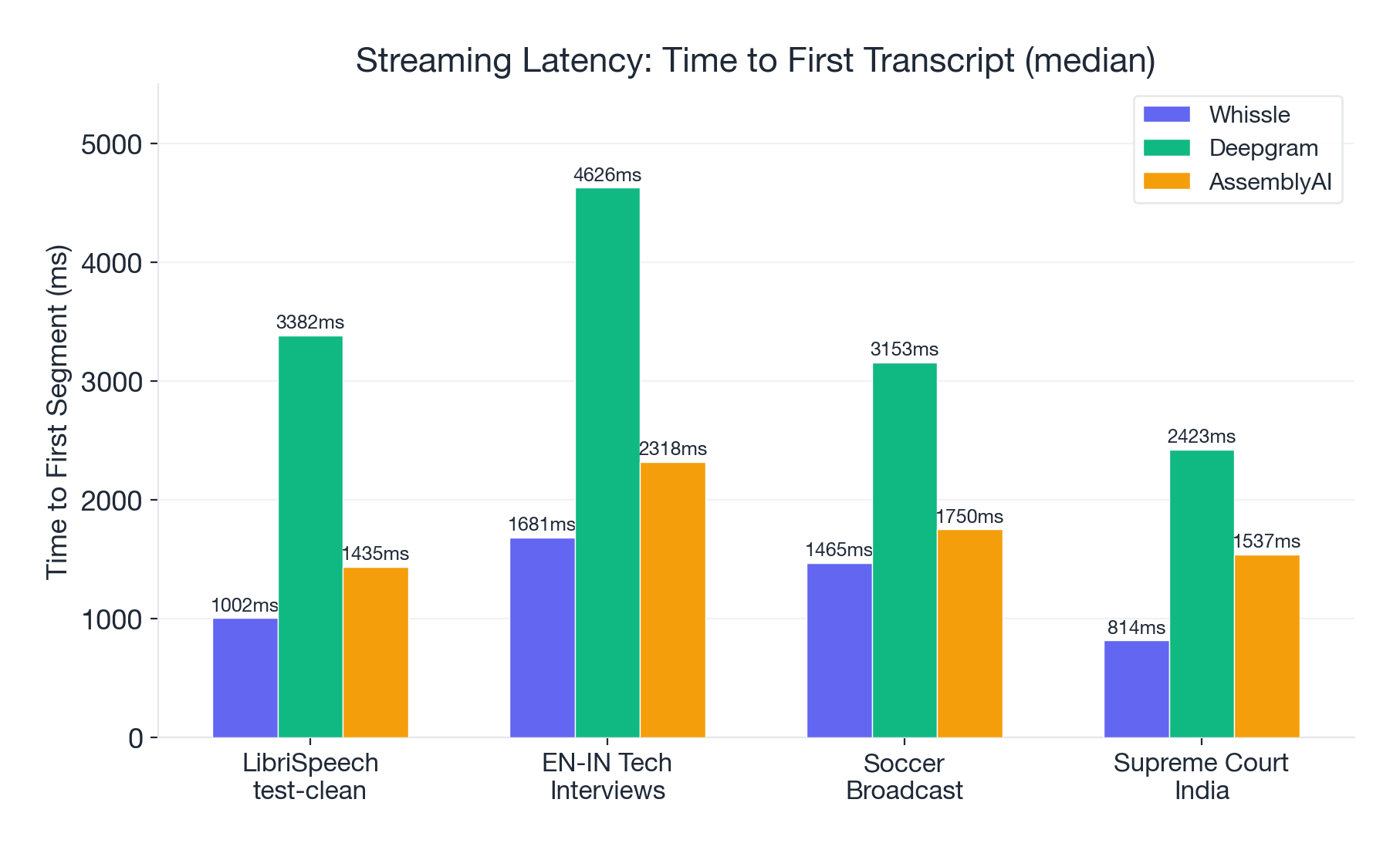
| Dataset | Whissle | Deepgram | AssemblyAI | Whissle Advantage |
|---|---|---|---|---|
| LibriSpeech | 1,002ms | 3,382ms | 1,435ms | 3.4x faster than DG |
| EN-IN Tech | 1,681ms | 4,626ms | 2,318ms | 2.8x faster than DG |
| Soccer | 1,465ms | 3,153ms | 1,750ms | 2.2x faster than DG |
| Court India | 814ms | 2,423ms | 1,537ms | 3.0x faster than DG |
Whissle delivers the first transcript 2--3x faster than Deepgram across every dataset. When a user is watching live captions or an agent needs to respond in real time, that ~2-second head start is the difference between "responsive" and "laggy."
Deepgram appears to buffer more audio before emitting its first transcript -- a tradeoff that likely contributes to its higher accuracy. Whissle prioritizes responsiveness.
Latency percentiles (LibriSpeech):
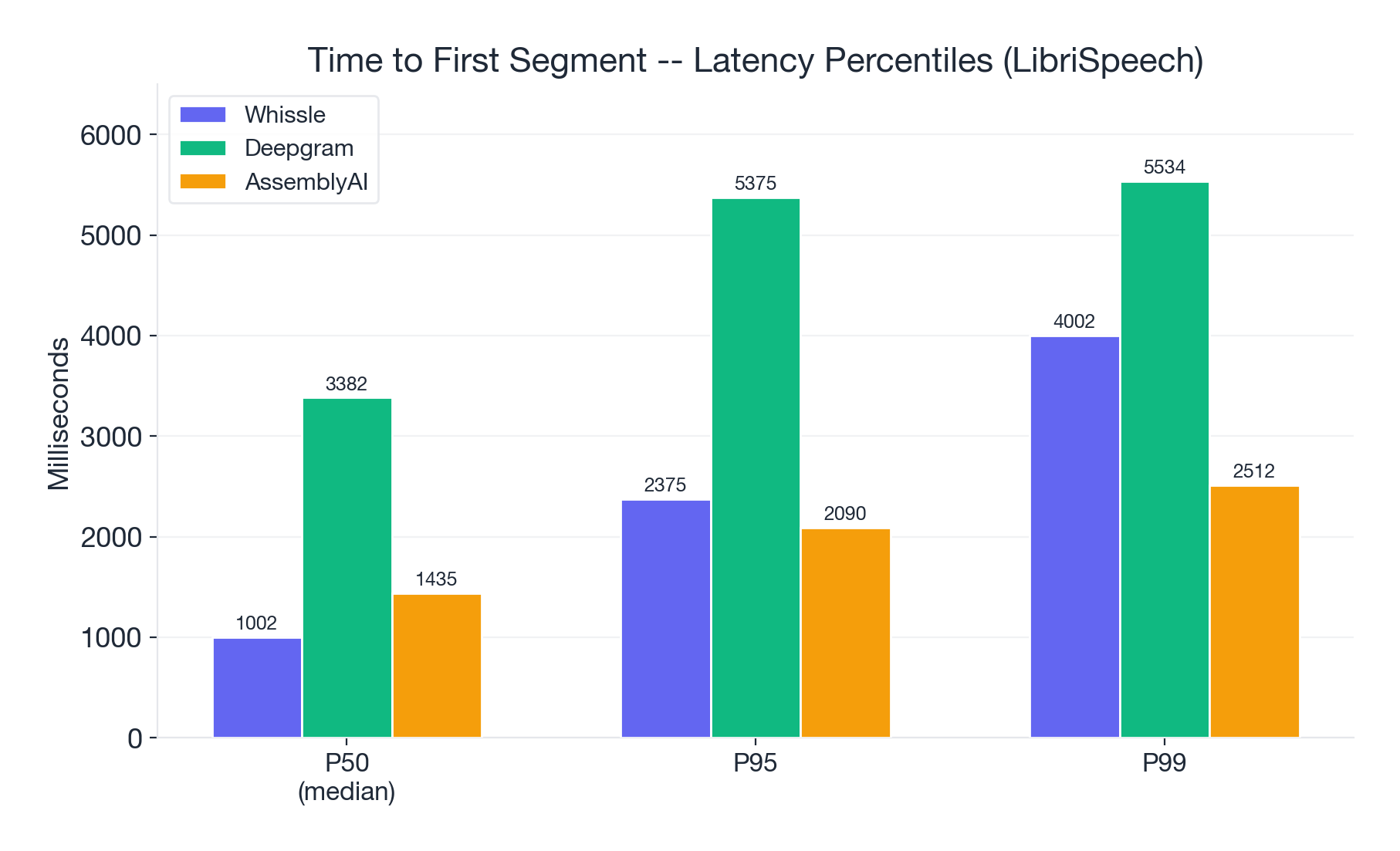
| Percentile | Whissle | Deepgram | AssemblyAI |
|---|---|---|---|
| P50 (median) | 1,002ms | 3,382ms | 1,435ms |
| P95 | 2,375ms | 5,375ms | 2,090ms |
| P99 | 4,002ms | 5,534ms | 2,512ms |
Even at the tail (P99), Whissle stays under 4 seconds. Deepgram's P95 and P99 are tightly clustered around 5.4s, suggesting a consistent buffering strategy rather than variance.
Reliability: One Provider Has a Serious Problem
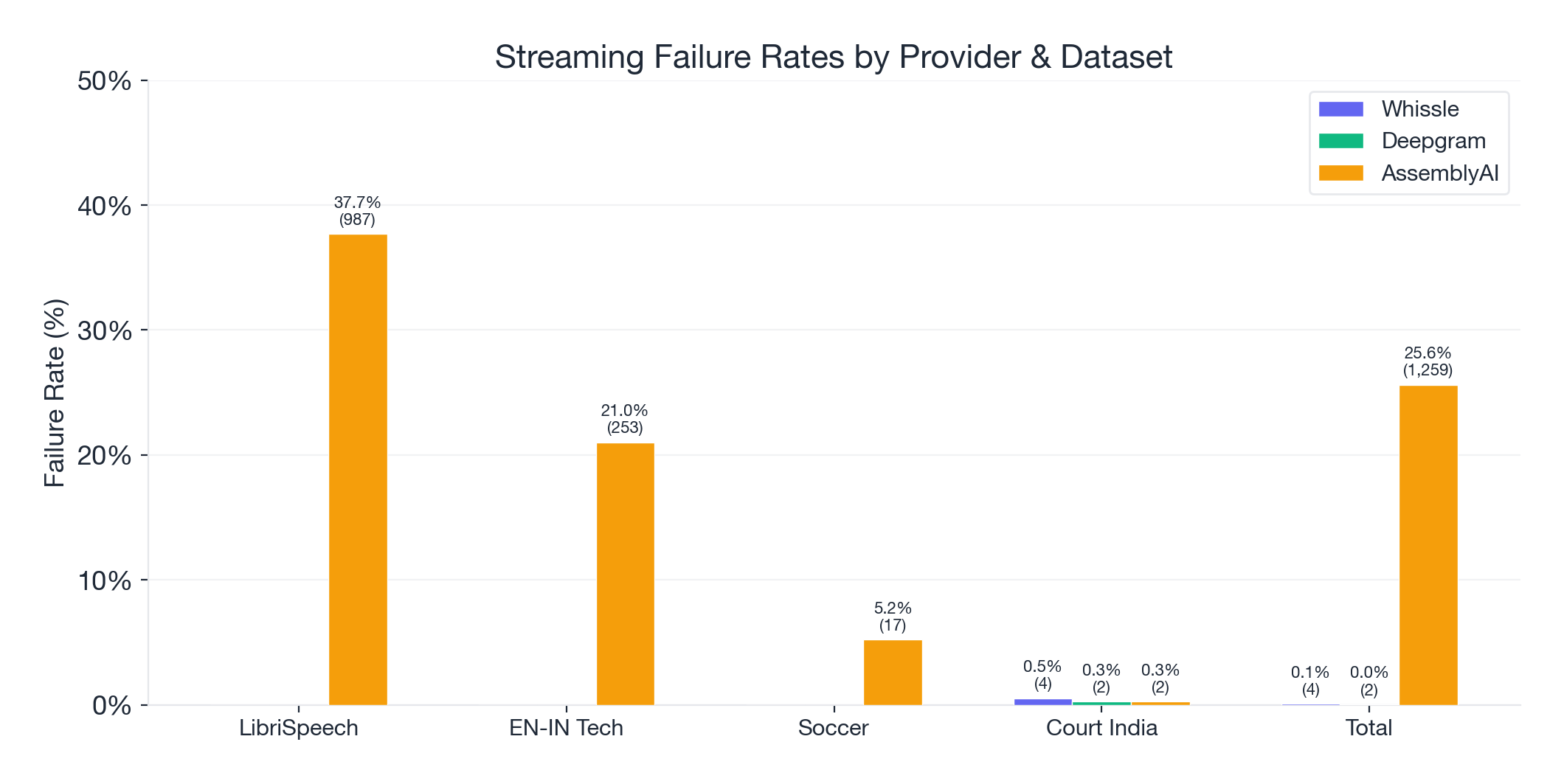
| Dataset | Whissle | Deepgram | AssemblyAI |
|---|---|---|---|
| LibriSpeech (2,620) | 0 (0.0%) | 0 (0.0%) | 987 (37.7%) |
| EN-IN Tech (1,204) | 0 (0.0%) | 0 (0.0%) | 253 (21.0%) |
| Soccer (327) | 0 (0.0%) | 0 (0.0%) | 17 (5.2%) |
| Court India (764) | 4 (0.5%) | 2 (0.3%) | 2 (0.3%) |
| Total (4,915) | 4 (0.08%) | 2 (0.04%) | 1,259 (25.6%) |
AssemblyAI's V3 streaming API failed to return a transcript for one in four samples overall -- driven almost entirely by catastrophic failure rates on LibriSpeech (37.7%) and EN-IN Tech (21.0%). On the court dataset, all three providers had a handful of failures, but the numbers are negligible.
When we adjust AssemblyAI's WER to account for failures (treating each failed sample as 100% WER), its LibriSpeech number jumps from 12.55% to 45.49%. Its accuracy advantage on soccer disappears entirely.
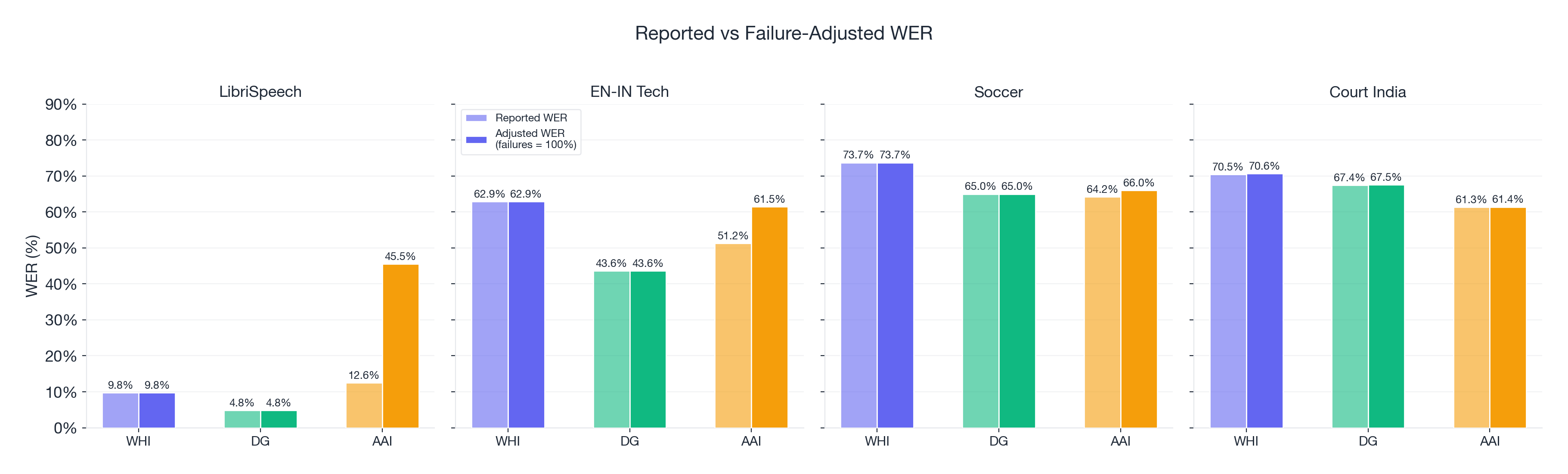
This is worth emphasizing: AssemblyAI's published WER numbers only reflect the samples that worked. For any production application, reliability is a prerequisite, not a feature.
Deep Dive: Where the Errors Happen
Raw WER numbers tell you how much a provider gets wrong. Error type analysis tells you how it gets things wrong -- and that pattern reveals something important about each provider's architecture.
Error Composition
Every transcription error is one of three types:
- Substitution -- the wrong word ("cat" instead of "cap")
- Deletion -- a word was dropped entirely
- Insertion -- a word was hallucinated that wasn't spoken
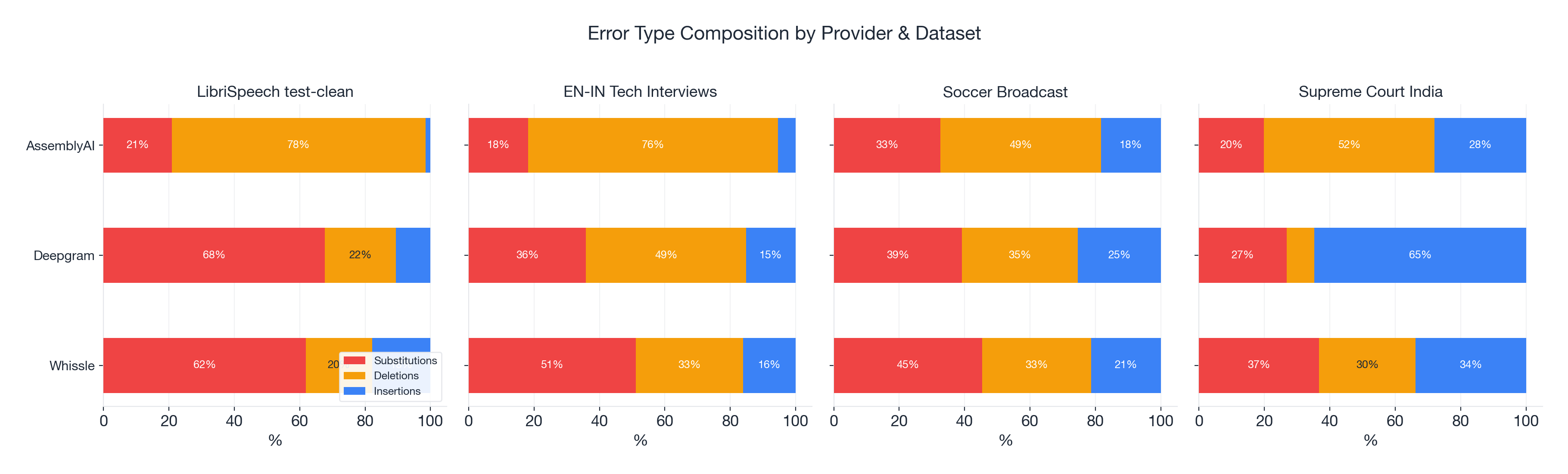
Whissle has a balanced, substitution-dominant profile. On LibriSpeech: 62% substitutions, 20% deletions, 18% insertions. This is the typical acoustic model pattern -- the model hears something but gets the word wrong. As conditions get harder, the deletion rate creeps up, but the profile stays balanced.
Deepgram shifts strategy between clean and difficult audio. On clean speech: 68% substitutions. On accented speech: 49% deletions. It becomes more conservative -- dropping words it's uncertain about rather than guessing. Better to omit than to hallucinate.
AssemblyAI is deletion-dominant everywhere. LibriSpeech: 78% deletions. EN-IN Tech: 76% deletions. Combined with its 26% failure rate, this points to a systemic issue in the streaming pipeline -- segments being dropped, turns ending prematurely, or transcripts being truncated.
| Provider | LibriSpeech | EN-IN Tech | Soccer | Court India | Pattern |
|---|---|---|---|---|---|
| Whissle | 62% sub / 20% del / 18% ins | 51% sub / 33% del / 16% ins | 45% sub / 33% del / 21% ins | 37% sub / 30% del / 34% ins | Balanced, substitution-led |
| Deepgram | 68% sub / 22% del / 11% ins | 36% sub / 49% del / 15% ins | 39% sub / 36% del / 25% ins | 27% sub / 8% del / 65% ins | Shifts strategy per dataset |
| AssemblyAI | 21% sub / 78% del / 2% ins | 18% sub / 76% del / 5% ins | 33% sub / 49% del / 18% ins | 20% sub / 52% del / 28% ins | Deletion-dominant |
The Degradation Problem
How much does each provider degrade from clean speech to real-world audio?
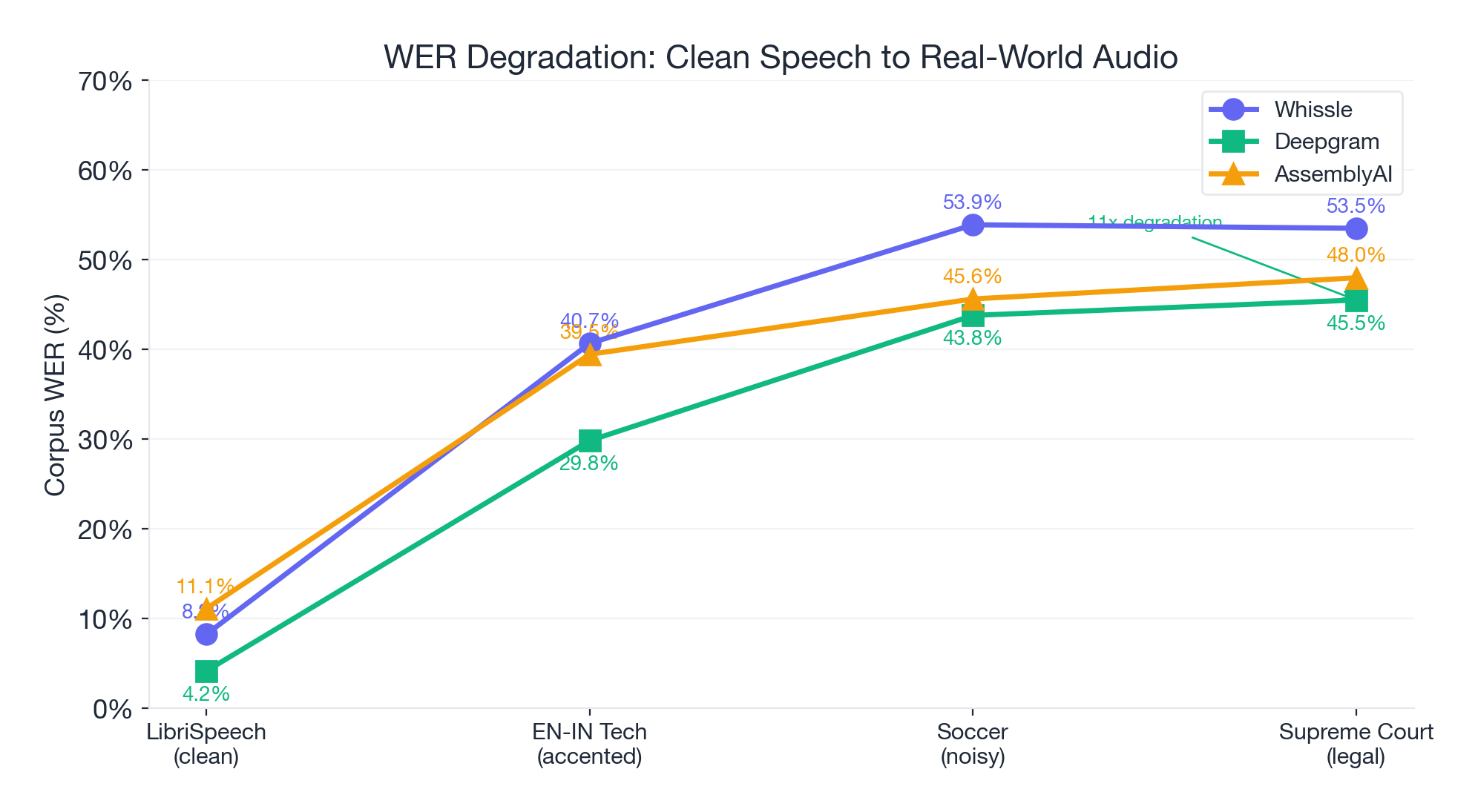
| Provider | LibriSpeech (clean) | EN-IN (accented) | Degradation | Soccer (noisy) | Degradation | Court India (legal) | Degradation |
|---|---|---|---|---|---|---|---|
| Whissle | 8.24% | 40.67% | 4.9x | 53.89% | 6.5x | 53.50% | 6.5x |
| Deepgram | 4.16% | 29.83% | 7.2x | 43.79% | 10.5x | 45.50% | 10.9x |
| AssemblyAI | 11.11% | 39.45% | 3.6x | 45.62% | 4.1x | 47.98% | 4.3x |
Deepgram has the best absolute numbers everywhere -- but it also degrades the most dramatically. Its 4.16% on LibriSpeech balloons 10.9x to 45.50% on court proceedings. This suggests its LibriSpeech excellence may partly reflect optimization for clean read speech rather than generalized robustness.
This is the central insight of this benchmark: LibriSpeech performance is a poor predictor of real-world performance. The provider with the best clean-speech score may not maintain that lead on your actual audio.
The WER Distribution Story
Mean WER tells you the average. But the distribution tells you what to actually expect.
WER by Duration (LibriSpeech)
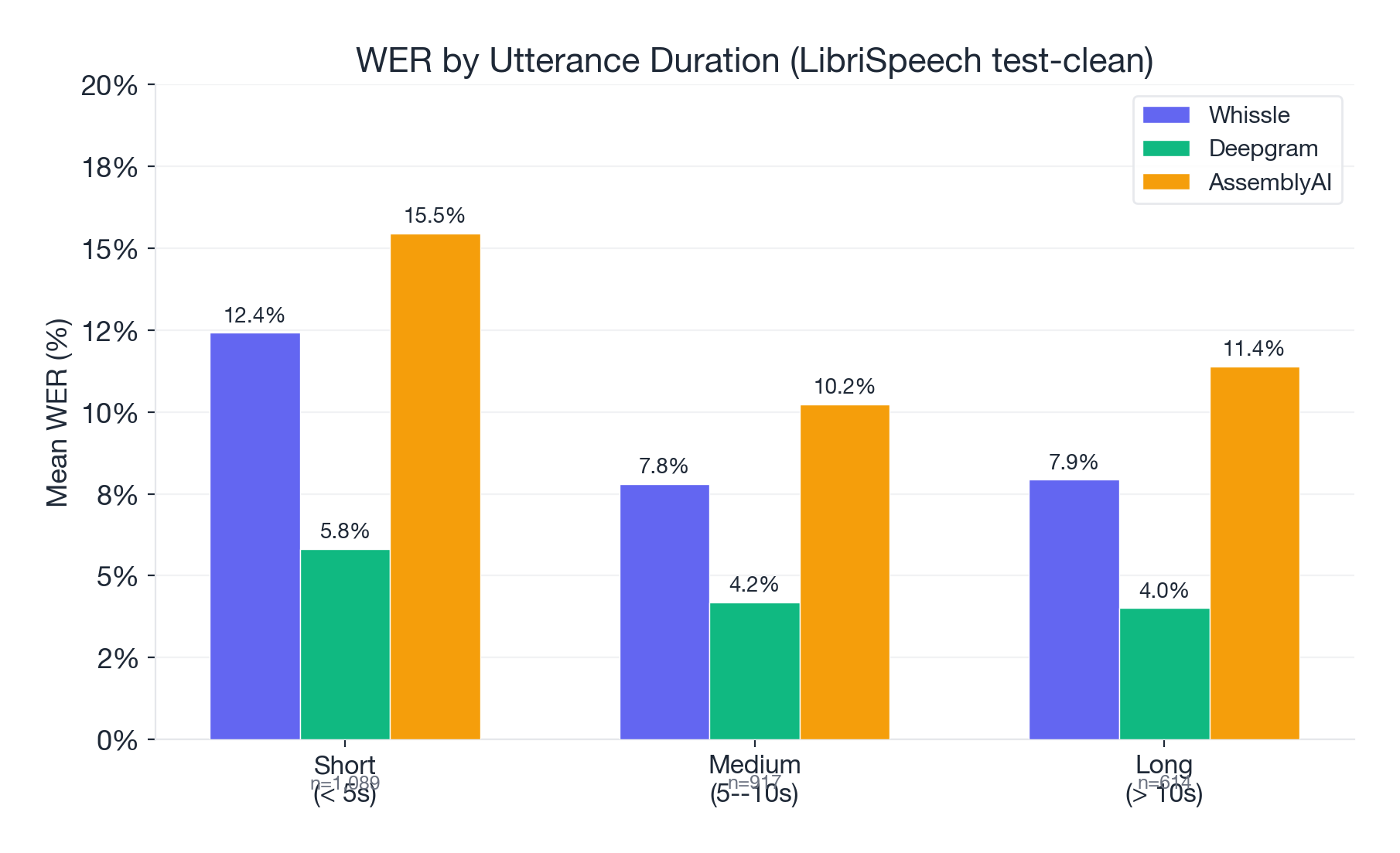
| Duration | Whissle | Deepgram | AssemblyAI | Samples |
|---|---|---|---|---|
| Short (< 5s) | 12.42% | 5.82% | 15.46% | 1,089 |
| Medium (5--10s) | 7.81% | 4.19% | 10.23% | 917 |
| Long (> 10s) | 7.93% | 4.01% | 11.39% | 614 |
All providers improve on longer utterances (more context for language model rescoring). Deepgram's advantage is consistent across all duration buckets.
WER Brackets
LibriSpeech -- what percentage of samples fall into each quality bracket?
| Bracket | Whissle | Deepgram | AssemblyAI* |
|---|---|---|---|
| Perfect (0% WER) | 901 (34.4%) | 1,532 (58.5%) | 446 (27.3%) |
| Excellent (≤ 10%) | 1,723 (65.8%) | 2,235 (85.3%) | 1,046 (64.1%) |
| Good (≤ 20%) | 2,277 (86.9%) | 2,485 (94.8%) | 1,351 (82.7%) |
| Poor (> 50%) | 40 (1.5%) | 14 (0.5%) | 84 (5.1%) |
| Total failure (≥ 100%) | 9 (0.3%) | 8 (0.3%) | 11 (0.7%) |
*AssemblyAI percentages based on 1,633 successful samples only (987 failed)
EN-IN Tech Interviews -- where things get uncomfortable for everyone:
| Bracket | Whissle | Deepgram | AssemblyAI* |
|---|---|---|---|
| Perfect (0% WER) | 13 (1.1%) | 62 (5.2%) | 31 (3.3%) |
| Good (≤ 20%) | 156 (13.0%) | 471 (39.1%) | 250 (26.3%) |
| Poor (> 50%) | 487 (40.4%) | 381 (31.7%) | 394 (41.4%) |
| Total failure (≥ 100%) | 247 (20.5%) | 272 (22.6%) | 194 (20.4%) |
*AssemblyAI percentages based on 951 successful samples only (253 failed)
On accented speech, even the best provider gets fewer than 4 in 10 samples to "good" accuracy. This isn't a provider problem -- it's an industry problem. Accented ASR is far from solved.
Soccer Broadcast: Zero samples achieved perfect transcription for any provider. Not a single 30-second broadcast segment was transcribed without at least one error.
Streaming vs. Batch: Does Pre-Recorded Mode Help?
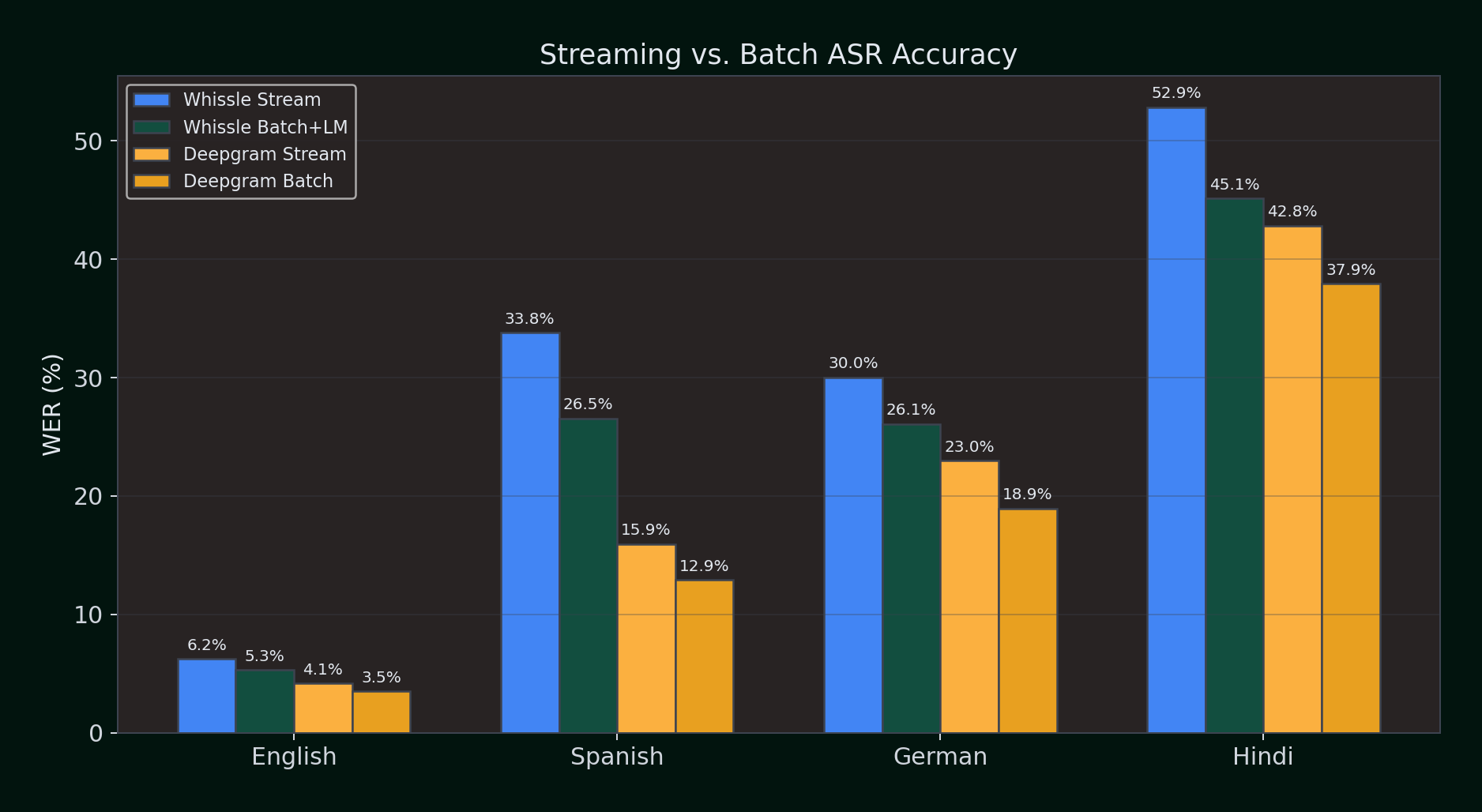
Streaming ASR processes audio in real time as it arrives. Batch (pre-recorded) ASR processes the entire audio file at once, giving the engine access to full context before producing output. Does this make a difference?
We ran identical audio through both streaming and batch APIs for Whissle and Deepgram across all four languages (100 samples each, 1000 for Hindi). For Whissle batch, we tested both greedy decoding and KenLM language model rescoring.
Streaming vs. Batch WER (%) -- lower is better:
| Language | Whissle Stream | Whissle Batch | Whissle Batch+LM | Deepgram Stream | Deepgram Batch |
|---|---|---|---|---|---|
| English | 6.21% | 5.63% | 5.31% | 4.14% | 3.48% |
| Spanish | 33.81% | 27.70% | 26.54% | 15.93% | 12.92% |
| German | 30.03% | 28.73% | 26.09% | 22.96% | 18.95% |
| Hindi | 52.86% | 48.76% | 45.15% | 42.84% | 37.91% |
Key observations:
- Batch consistently improves WER for both providers. Having the full audio context before decoding helps -- expected, since batch engines can look ahead and resolve ambiguities.
- Whissle's LM rescoring adds 1--4% absolute improvement on top of batch greedy decoding. The KenLM n-gram model catches spelling and grammar errors that pure CTC decoding misses.
- Deepgram's batch mode narrows the gap -- in English, Deepgram batch (3.48%) approaches Gemini 2.0 Flash (3.12%), the accuracy leader.
- Streaming is the harder problem. Every provider does better in batch mode. The question is whether your use case can wait for the full audio -- if you're building real-time applications (live captioning, call coaching, voice agents), streaming is not optional.
Batch mode is the right choice for post-call analytics, media transcription, and any workflow where latency doesn't matter. But for live applications, streaming accuracy is what counts -- and that's where the architectural differences between CTC-based streaming (Whissle) and proprietary streaming (Deepgram) become the deciding factor.
Beyond Transcription: Streaming Metadata
Here's where the comparison shifts from "who has the lowest WER" to "who gives you the most useful output."
All providers return transcripts with word timestamps and confidence scores. But the metadata landscape varies significantly -- and the delivery mode matters as much as the feature list:
| Feature | Whissle | Deepgram | AssemblyAI | Gemini 2.0 Flash |
|---|---|---|---|---|
| Transcription | Yes | Yes | Yes | Yes |
| Word timestamps | Yes | Yes | Yes | -- |
| Word confidence | Yes | Yes | Yes | -- |
| Interim/partial results | Yes | Yes | Yes | -- |
| Emotion detection | Yes (real-time, 7 classes) | Batch only (Sentiment) | Batch only (Sentiment) | Batch only (via prompt) |
| Intent classification | Yes (real-time, 6 classes) | Batch only | -- | Batch only (via prompt) |
| Speaker change detection | Yes (in-stream) | -- | -- | -- |
| Speaker demographics | Yes (age, gender) | -- | -- | -- |
| Speech rate (WPM) | Yes | -- | -- | -- |
| Filler word detection | Yes | -- | -- | -- |
| Emotion probabilities | Yes (per-segment) | -- | -- | -- |
| Intent probabilities | Yes (per-segment) | -- | -- | -- |
| Speaker diarization | -- | Add-on (streaming) | Batch only | -- |
| Topic detection | -- | Batch only | Batch only | Batch only (via prompt) |
| Entity detection | Via in-stream tokens | Batch only | Batch only | Batch only (via prompt) |
| Summarization | -- | Batch only (EN) | Batch only | Batch only (via prompt) |
| Delivery mode | Streaming WebSocket | Streaming + batch add-ons | Streaming + batch add-ons | Batch API only |
| Metadata latency | ~200ms (included) | 887--1,233ms (separate call) | Separate batch call | 1,819--2,219ms (separate call) |
Deepgram and AssemblyAI offer sentiment, intent, and entity features in their batch/pre-recorded APIs, but in streaming mode these are not available. Gemini 2.0 Flash can extract any metadata via prompting -- but only in batch mode, with 1.8--2.4 second latency per utterance. Deepgram's streaming add-on for speaker diarization is a notable exception.
Whissle streams all of the following in real time -- as part of the same WebSocket connection, with zero additional latency:
- Emotion detection -- per-segment classification across 7 emotions with full probability distributions
- Intent classification -- 20+ intent categories (inform, question, command, describe, etc.) with probabilities
- Speaker change detection -- in-stream tokens marking when the speaker changes
- Speech rate -- words per minute, measured in real time
- Filler word detection -- counts of "um", "uh", "like", "you know"
- Speaker demographics -- age range and gender classification
Metadata Coverage
| Dataset | Samples | Emotion Detected | Intent Detected | WPM Measured |
|---|---|---|---|---|
| LibriSpeech | 2,620 | 2,620 (100%) | 2,620 (100%) | 2,618 (99.9%) |
| EN-IN Tech | 1,204 | 1,088 (90.4%) | 1,088 (90.4%) | 1,060 (88.0%) |
| Soccer | 327 | 327 (100%) | 327 (100%) | 327 (100%) |
| Court India | 764 | 760 (99.5%) | 760 (99.5%) | 756 (99.0%) |
Metadata Evaluation: Emotion Detection
The soccer broadcast dataset includes human-annotated ground truth for emotion, intent, age, and gender -- allowing us to evaluate Whissle's metadata predictions against labels.
Emotion distribution across datasets:
| Emotion | LibriSpeech | EN-IN Tech | Soccer | Court India |
|---|---|---|---|---|
| Neutral | 2,173 (82.9%) | 1,082 (99.4%) | 326 (99.7%) | 276 (36.3%) |
| Angry | 216 (8.2%) | 2 (0.2%) | -- | 277 (36.4%) |
| Happy | 133 (5.1%) | 1 (0.1%) | 1 (0.3%) | 207 (27.2%) |
| Disgust | 62 (2.4%) | 1 (0.1%) | -- | -- |
| Surprise | 16 (0.6%) | 1 (0.1%) | -- | -- |
| Sad | 15 (0.6%) | 1 (0.1%) | -- | -- |
| Fear | 5 (0.2%) | -- | -- | -- |
LibriSpeech (audiobook narration) shows emotional variety -- professional narrators use distinct vocal tones for different characters and dramatic moments, which the model picks up. Tech interviews are almost entirely neutral, as expected for professional conversations. Soccer broadcast commentary is acoustically neutral even when describing exciting moments.
The Supreme Court dataset shows the most interesting emotion distribution: roughly equal parts angry (36.4%), neutral (36.3%), and happy (27.2%). This reflects the adversarial nature of courtroom proceedings -- advocates argue forcefully (detected as angry), judges maintain composure (neutral), and favorable rulings or successful arguments produce positive vocal tones (happy). Unlike soccer commentary where acoustic emotion is muted, courtroom speech carries genuine vocal intensity.
Ground truth comparison (Soccer Broadcast, 327 samples):
| Ground Truth Emotion | Samples | Whissle Correct | Recall |
|---|---|---|---|
| Neutral | 202 | 202 | 100.0% |
| Happy | 66 | 1 | 1.5% |
| Sad | 59 | 0 | 0.0% |
| Overall accuracy | 327 | 203 | 62.1% |
An important nuance: the ground truth labels in the soccer dataset annotate contextual emotion (happy when a goal is scored, sad when a chance is missed), while Whissle detects acoustic emotion (the actual tone of voice). Professional broadcast commentators maintain a relatively even vocal tone regardless of context -- a commentator describing a goal doesn't necessarily sound acoustically "happy" in the way a person celebrating would. The 100% recall on neutral reflects that the model is accurately reading the acoustic signal, even when the annotated context differs.
Metadata Evaluation: Intent Classification
Intent distribution across datasets (EN-IN percentages based on 1,088 samples with detected intent; 116 very short segments returned no intent):
| Intent | LibriSpeech | EN-IN Tech | Soccer | Court India |
|---|---|---|---|---|
| Inform | 2,337 (89.2%) | 1,054 (96.9%) | 326 (99.7%) | 752 (98.9%) |
| Question | 151 (5.8%) | 28 (2.6%) | 1 (0.3%) | 6 (0.8%) |
| Describe | 67 (2.6%) | -- | -- | -- |
| Command | 29 (1.1%) | 4 (0.4%) | -- | 1 (0.1%) |
| Other | 36 (1.4%) | 2 (0.2%) | -- | 1 (0.1%) |
The soccer dataset has domain-specific ground truth intents (Play-by-play, Analysis, Statistic, Reaction). Whissle uses a general-purpose intent taxonomy. When we map the domain-specific labels to their general equivalents (Play-by-play/Analysis/Statistic map to Inform), the alignment accuracy is 99.7% (326/327) -- the model correctly identifies that commentary is fundamentally informational speech.
LibriSpeech shows more intent variety because audiobook narration includes dialogue with questions (5.8%), descriptive passages (2.6%), and imperative speech (1.1%). Tech interviews are overwhelmingly informational with occasional questions -- consistent with interview dynamics. Court proceedings are similarly dominated by informational speech (98.9%) -- advocates presenting arguments and judges delivering rulings -- with occasional questions from the bench (0.8%).
Speech Rate Analysis
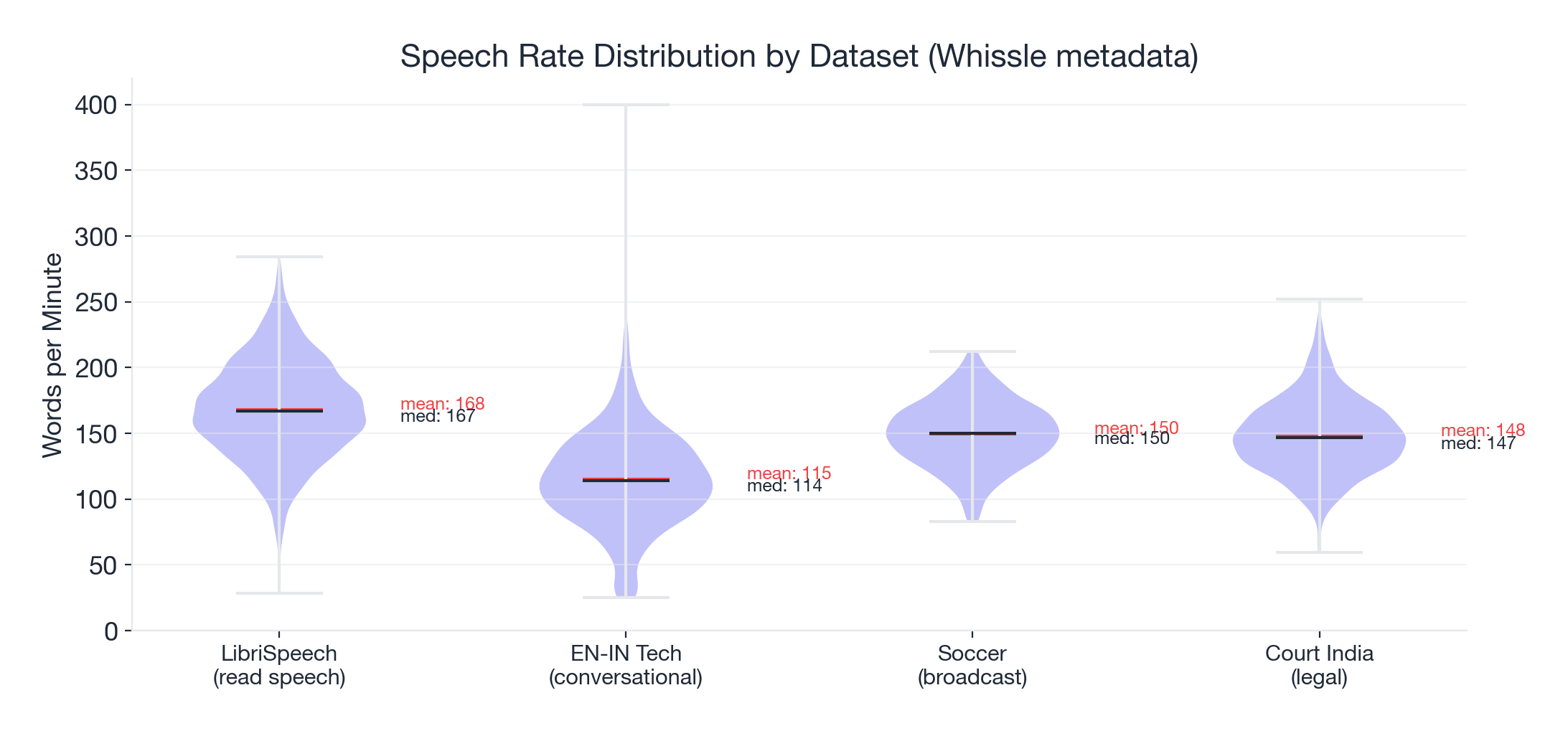
| Dataset | Mean WPM | Median WPM | Range |
|---|---|---|---|
| LibriSpeech (read speech) | 168.2 | 166.9 | 28.4 -- 284.0 |
| EN-IN Tech (conversational) | 115.2 | 114.3 | 25.0 -- 400.0 |
| Soccer (broadcast) | 149.7 | 150.0 | 83.0 -- 212.5 |
| Court India (legal) | 148.1 | 146.6 | 59.8 -- 252.2 |
LibriSpeech shows the highest speech rate (professional narrators reading at a steady pace). Tech interviews are slower (thinking pauses, technical explanations). Soccer commentary and court proceedings sit in between at similar median rates (~150 WPM), though court speech shows a wider range -- from measured judicial deliberation to rapid-fire advocacy.
Why Metadata Changes Everything
If you're building live captioning, a transcription API is enough. But if you're building anything that needs to understand the conversation -- not just record it -- you need more than words.
1. Detect escalations before they happen. Real-time emotion detection flags when a customer's tone shifts from neutral to frustrated -- before they ask for a manager. Intent classification distinguishes a genuine question from a complaint. In a call center, this means routing to a supervisor in seconds, not minutes.
2. Coach speakers in real time. Speech rate tracking tells presenters they're rushing. Filler word counts ("um", "uh", "like") show job candidates exactly what to work on. All streamed live during the conversation, not buried in a post-call report.
3. Understand conversations, not just words. Speaker change detection identifies turn-taking patterns. Demographics reveal who's dominating a meeting. Intent classification distinguishes questions from statements from commands. These signals transform a flat transcript into a structured understanding of what actually happened.
4. Ship with confidence. Near-zero failures across 4,915 samples means virtually every audio segment returns a transcript plus metadata. No silent drop-outs, no missing data, no fallback logic needed. Getting all of this in a single streaming WebSocket connection, with zero additional latency at the same per-minute price, is a fundamentally different value proposition.
Metadata Extraction: The Hidden Latency Cost
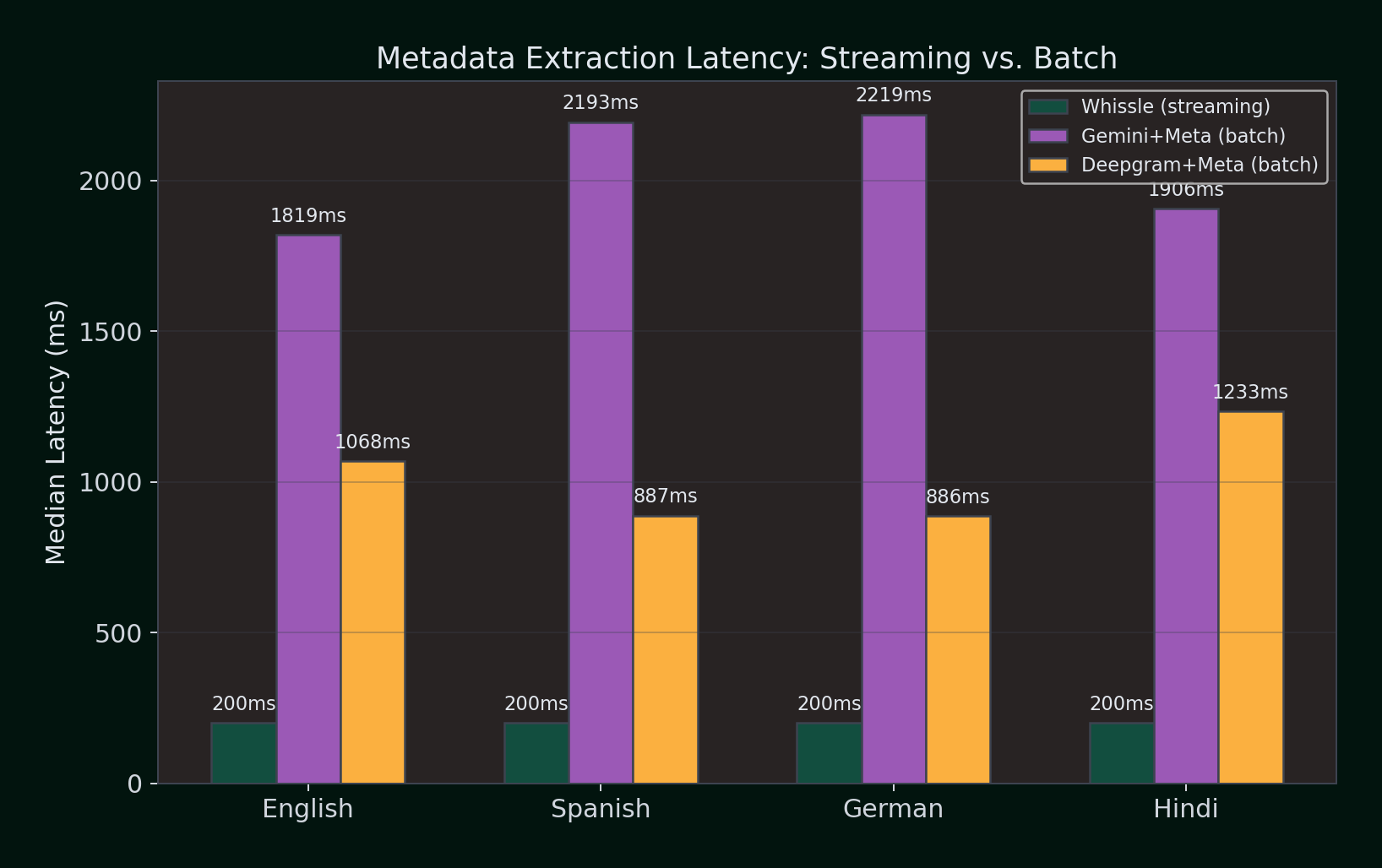
Competitors offer metadata features -- but as separate batch API calls that add latency and cost on top of transcription. We benchmarked the real cost of getting metadata from each provider across four languages (100 samples per language).

What each provider returns with metadata enabled:
| Feature | Whissle (streaming) | Gemini 2.0 Flash (batch) | Deepgram Nova-3 (batch) |
|---|---|---|---|
| Transcription | Yes | Yes | Yes |
| Emotion (7 classes) | Yes -- real-time | Yes -- batch* | -- |
| Intent (6 classes) | Yes -- real-time | Yes -- batch* | Yes -- batch |
| Sentiment | Yes -- real-time | Yes -- batch* | Yes -- batch |
| Topics | -- | Yes -- batch* | Yes -- batch |
| Named entities | Via in-stream tokens | Yes -- batch* | Yes -- batch |
| Summarization | -- | -- | Yes -- batch (EN only) |
| Emotion probabilities | Yes (per-segment) | -- | -- |
| Intent probabilities | Yes (per-segment) | -- | -- |
| Speech rate (WPM) | Yes -- real-time | -- | -- |
| Filler detection | Yes -- real-time | -- | -- |
| Speaker demographics | Yes -- real-time | -- | -- |
* Gemini metadata is extracted via LLM prompt -- accurate but batch-only with variable latency.
Transcription accuracy with metadata enabled (WER %):
| Language | Deepgram streaming | Gemini+Meta (batch) | Deepgram+Meta (batch) |
|---|---|---|---|
| English | 4.14% | 3.72% | 2.86% |
| Spanish | 15.09% | 12.48% | 13.26% |
| German | 23.01% | 17.77% | 18.38% |
| Hindi | 37.17% | 23.52% | 27.11% |
Median latency to get transcript + metadata (ms):
| Language | Whissle (streaming) | Gemini+Meta (batch) | Deepgram+Meta (batch) |
|---|---|---|---|
| English | ~200ms | 1,819ms | 1,068ms |
| Spanish | ~200ms | 2,193ms | 887ms |
| German | ~200ms | 2,219ms | 886ms |
| Hindi | ~200ms | 1,906ms | 1,233ms |
Whissle's streaming metadata arrives at ~200ms as part of the same WebSocket connection -- before competitors even finish their batch API calls. Deepgram's batch metadata API takes 886--1,233ms per utterance. Gemini's LLM-based extraction takes 1,819--2,219ms. Both require a separate API call after transcription, meaning the total pipeline latency is transcription time + metadata extraction time.
For a streaming use case processing 10 utterances per minute, the metadata overhead alone adds:
- Whissle: 0ms additional (included in streaming response)
- Deepgram batch meta: ~10s of additional API calls per minute
- Gemini meta: ~20s of additional API calls per minute
Label taxonomy alignment: Both Whissle and Gemini use the same emotion labels (EMOTION_NEUTRAL, EMOTION_HAPPY, EMOTION_SAD, EMOTION_ANGRY, EMOTION_FEAR, EMOTION_SURPRISE, EMOTION_DISGUST) and intent labels (INTENT_INFORM, INTENT_QUESTION, INTENT_COMMAND, INTENT_AFFIRM, INTENT_OTHER). Deepgram's batch API returns sentiment (positive/negative/neutral) rather than fine-grained emotion classes -- a coarser signal that conflates emotion with opinion polarity.
The takeaway: Gemini and Deepgram can extract metadata, but only after the audio is fully processed, only via batch APIs, and at significant latency cost. Whissle delivers richer metadata -- including emotion probabilities, intent probabilities, speech rate, and filler detection -- in real time, as part of the same streaming connection, with zero additional latency or cost.
Confidence Scores: Who's Honest About Uncertainty?
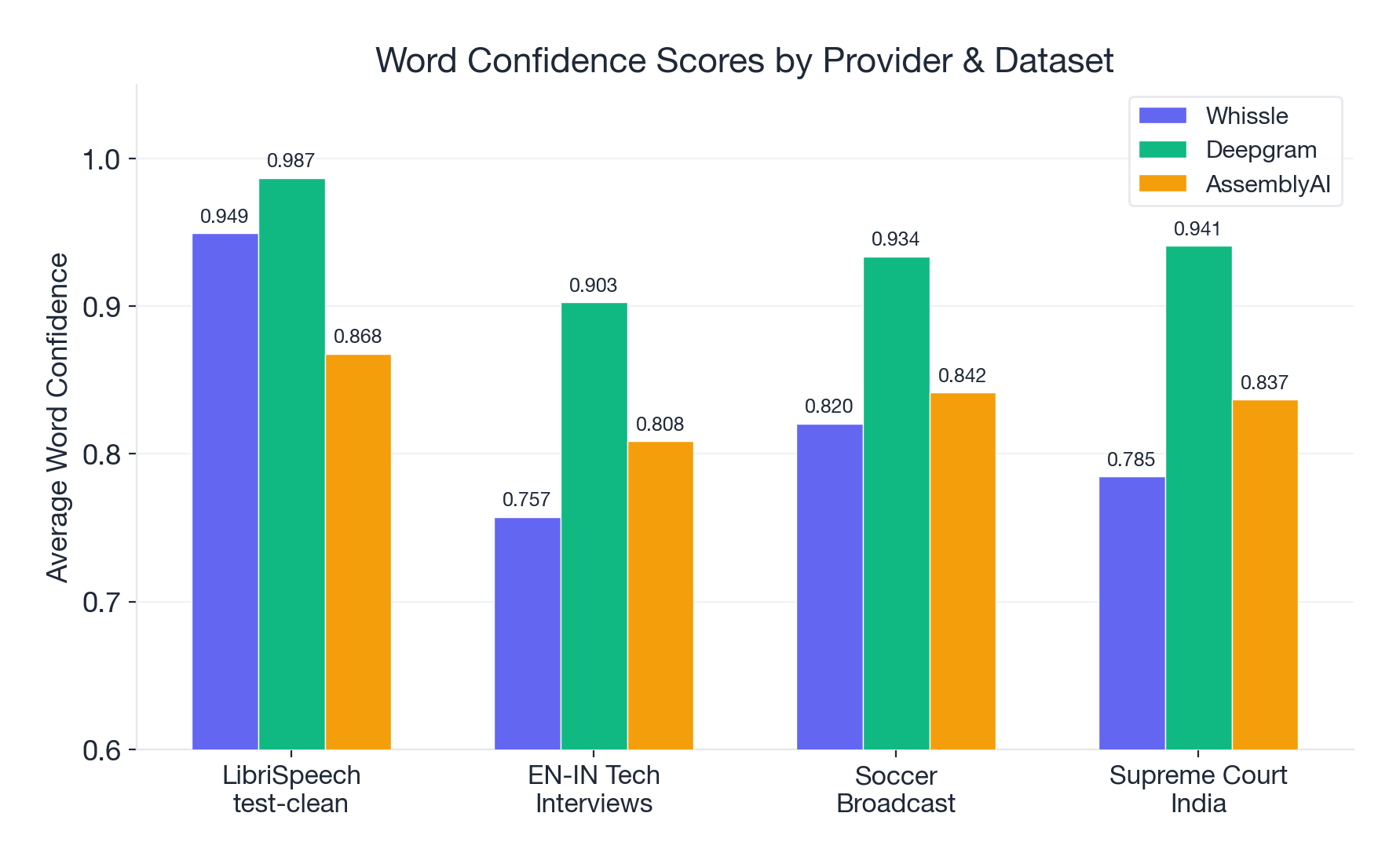
| Dataset | Whissle | Deepgram | AssemblyAI |
|---|---|---|---|
| LibriSpeech | 0.949 | 0.987 | 0.868 |
| EN-IN Tech | 0.757 | 0.903 | 0.809 |
| Soccer | 0.820 | 0.934 | 0.842 |
| Court India | 0.785 | 0.941 | 0.837 |
Deepgram's confidence is high and justified -- it has the best WER and the highest confidence. Well calibrated.
Whissle's confidence drops sharply from 0.949 on clean speech to 0.757 on accented speech -- a 20-point drop that honestly reflects the increased difficulty. If you're building a system that needs to know when to trust the transcript less, Whissle's confidence is informative.
AssemblyAI's confidence stays between 0.81 and 0.87 across all datasets -- even though its WER is the worst on LibriSpeech and it has a 26% failure rate. The confidence doesn't drop proportionally to accuracy.
A confidence score is only useful if low confidence actually predicts errors. Whissle's confidence is honest -- it goes down when things get hard. AssemblyAI's confidence stays high regardless.
Pricing and Deployment
| Whissle | Deepgram | AssemblyAI | Gemini 2.0 Flash | |
|---|---|---|---|---|
| Cost per audio minute | $0.0043 | $0.0043 | $0.0050 | ~$0.001* |
| Cost per audio hour | $0.258 | $0.258 | $0.300 | ~$0.06* |
| What's included | Transcription + emotion, intent, speaker change, WPM, fillers, demographics | Transcription only (metadata features are add-ons) | Transcription only | Transcription + metadata via prompt |
| Streaming support | Yes (WebSocket) | Yes (WebSocket) | Yes (WebSocket) | No (batch only) |
| Deployment options | Cloud API + self-hosted Docker | Cloud API only | Cloud API only | Cloud API only |
| Self-hosted option | Yes (eliminates per-minute costs) | No | No | No |
* Gemini pricing is per-token, not per audio minute. Cost varies by audio length and prompt. Estimate based on typical 10-second utterances.
Whissle matches Deepgram's base streaming transcription price at $0.0043 per audio minute -- but at that price, you get all metadata (emotion, intent, speaker change, speech rate, filler detection, demographics) included. With Deepgram, metadata features are paid add-ons on top of the base transcription cost. Gemini is the cheapest per-minute option, but the lack of streaming support makes it unsuitable for real-time applications.
For high-volume use cases, Whissle's self-hosted Docker deployment eliminates per-minute costs entirely -- critical for call centers, media processing, and organizations with data residency requirements.
Who Wins What?
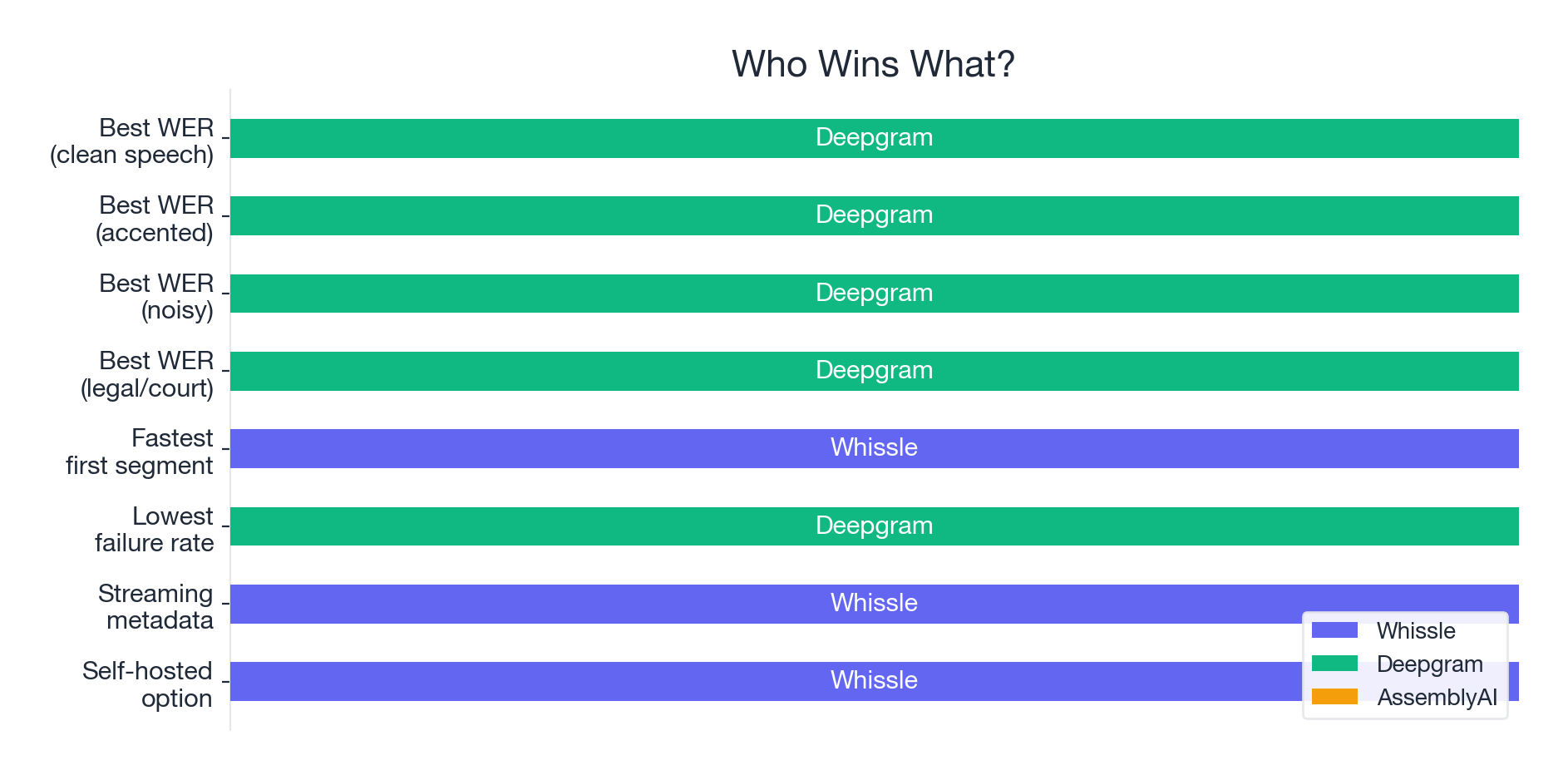
Choose Deepgram when:
- Transcription accuracy is your number one priority
- Your audio is primarily clean, well-recorded English
- You're comfortable with slightly higher first-segment latency (~3.4s)
- You need the best WER at competitive per-minute pricing
Choose Whissle when:
- You need the fastest first-segment response (1.0--1.7s) for real-time coaching, live captions, or conversational AI
- You need streaming emotion, intent, speech rate, or filler detection alongside transcription
- Near-zero failure rates are non-negotiable (medical, legal, safety, accessibility)
- You want to self-host ASR on your own infrastructure
- You're building beyond transcription -- coaching, analytics, meeting intelligence
Be cautious with AssemblyAI streaming:
- The V3 streaming API had a 25.6% failure rate across our benchmark
- When it works, accuracy is competitive -- but the failure rate makes it unreliable for production use
- The deletion-dominant error profile suggests systemic issues with the streaming pipeline
The Bigger Picture
Clean speech ASR is effectively solved. At 4--12% WER on LibriSpeech, we're in the range of human disagreement. Providers arguing over percentage points on clean speech are fighting the last war.
Real-world ASR is far from solved. The jump from 4% to 46% WER when you add accents, noise, and domain-specific vocabulary is not a small gap -- it's an 11x degradation. This is the frontier.
LibriSpeech benchmarks are misleading in isolation. A provider that's 2x better on LibriSpeech might be only 1.3x better on your actual audio -- or worse if their model is overfit to clean speech.
Reliability is a feature, not an assumption. One of three major providers failed on 26% of samples. Your test suite needs to measure failure rate, not just WER on the samples that succeed.
Batch metadata adds latency, not intelligence. Deepgram and Gemini can extract sentiment, intent, and entities -- but only through separate batch API calls that add 0.9--2.2 seconds per utterance. For a system processing 10 utterances per minute, that's 9--22 seconds of metadata overhead per minute. Whissle delivers richer metadata (emotion with probabilities, intent with probabilities, speech rate, filler detection, demographics) at zero additional latency, in the same streaming response.
Transcription is table stakes. The next wave of speech AI isn't about squeezing 0.5% more WER -- it's about what else you can extract from audio in real time. Emotion, intent, speech patterns, engagement signals. The provider that delivers these alongside transcription, without additional latency or cost, changes the application design space.
Cross-Dataset Summary
| Dataset | Samples | Audio | Whissle WER | Deepgram WER | AssemblyAI WER | AAI Failures |
|---|---|---|---|---|---|---|
| LibriSpeech test-clean | 2,620 | 5.40h | 9.75% | 4.83% | 12.55% | 987 (37.7%) |
| EN-IN Tech Interviews | 1,204 | 5.27h | 62.94% | 43.62% | 51.25% | 253 (21.0%) |
| Soccer Broadcast | 327 | 2.73h | 73.74% | 64.99% | 64.18% | 17 (5.2%) |
| Supreme Court India | 764 | 4.24h | 70.48% | 67.44% | 61.31% | 2 (0.3%) |
| Total | 4,915 | 17.64h | -- | -- | -- | 1,259 (25.6%) |
Methodology Appendix
Benchmark script: Open source, available in our repository. Uses HuggingFace datasets for LibriSpeech and EN-IN Tech, JSONL manifests for Soccer. Full per-sample JSON results published for independent verification.
Text normalization: Lowercase, strip all punctuation, collapse whitespace. For WhissleAI datasets, metadata tokens (AGE_*, GENDER_*, EMOTION_*, INTENT_*) and entity markers (ENTITY_*...END) stripped from reference text before comparison.
WER computation: jiwer library (standard implementation). Per-sample WER averaged for mean; total errors / total words for corpus WER.
Corpus WER vs Mean WER: Mean WER averages per-sample rates -- a 3-word utterance with 1 error scores 33% and weighs equally with a 100-word utterance. Corpus WER divides total errors by total words, giving proportional weight. We report both; corpus WER is generally more representative.
Infrastructure: Whissle on Cloud Run (CPU, ONNX runtime). Deepgram and AssemblyAI via their cloud APIs. All requests from the same machine. April 2026.
Reproducibility: All result JSONs (per-sample transcripts, WER, latency, metadata) are published. Every number in this post can be independently verified.
We built this benchmark because we believe the ASR industry needs more transparent, multi-dataset evaluations. If you want to run these tests yourself or add your own datasets, the tooling is open source.
If you're exploring ASR for your application, try the providers on your actual audio before making a decision. Benchmarks inform -- but your data decides.