Instant Audio-visual Intelligence For Multi-modal Input Streams
How do we know computers understand us? Human voice is a multi-modal medium, carrying layers of meaning through countless variations in tone, pitch, rhythm, emotion and context.
Present day digital voice assistants lack essential qualities to make them engaging and provide a experience, reflecting human-like empathy, context intelligence and improvement over time.
Over time this lack of harness of meta information in voice becomes more than just disappointing—it becomes exhausting, expensive and limiting.
Achieving Meta information capture
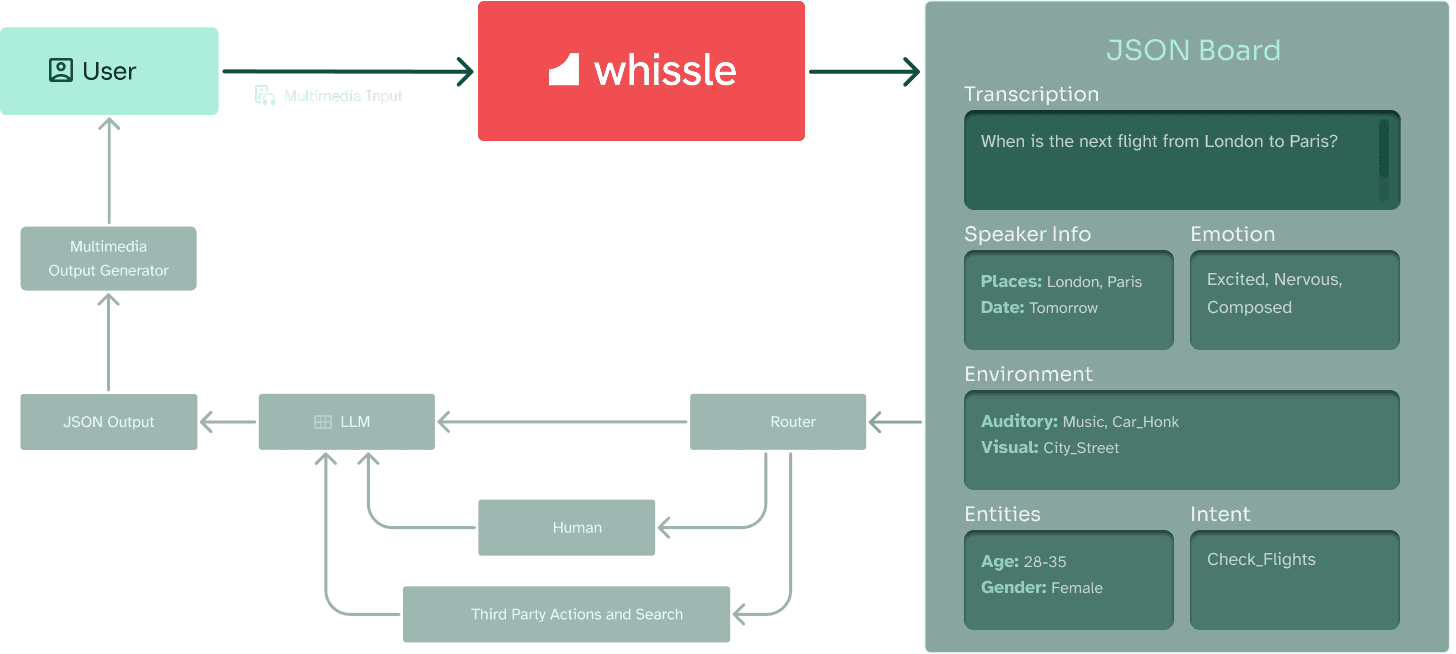
At Whissle, our goal is to achieve Meta information capture —the elusive quality that captures every subtlety of human speech so that our digital partners truly listen and understand. We are building conversational systems that dont just transcribe words; they perceive and interpret the layered aspects of voice, instilling confidence and trust through genuine human-like understanding. In doing so, we aim to harness the rich, untapped potential of voice as the ultimate channel for meaningful human-computer interaction.
Key components
- Emotional intelligence: identifying and responding to emotional cues in spoken language.
- Key entities and intent recognition: extracting meaningful information and understanding user goals.
- Contextual awareness: extracted information can be aware of last N mins of audio context.
- Environmental understanding: detecting acoustic noise and adapting responses accordingly.
- Speaker characteristics: identifying attributes like age and gender to personalize interactions.
- Action triggering: enabling direct IoT commands and voice controls based on captured information and semantic understanding.
Current capabilities
In addition to accurate transcription, our system currently captures crucial meta-information including key entities and intent, emotional states, acoustic noise levels, and speaker characteristics such as age and gender. This allows for more intelligent responses and enables practical applications like IoT device control and voice command execution.
We are continuing to evolve
Building a digital companion that truly understands spoken words, emotions, and intent is no small task. We continue to advance capabilities such as personality, memory, and context detection. This demo illustrates our progress in capturing nuanced speech information and interpreting it effectively. Our current focus is on transcribing and analyzing voice in a way that fosters deeper understanding—laying the groundwork for a future where computer listening feels as natural and supportive as a human conversation.
ARTICLES
Meta-aware Voice Action Model
Using Visuals for Better Sound Awareness
PUBLICATIONS
Visual-Aware Speech Recognition for Noisy Scenarios
We propose a model that improves transcription by correlating noise sources to visual cues from the environment, enabling the system to naturally filter speech from noise — much like humans do. Our method re-purposes pretrained speech and visual encoders linked with multi-headed attention, showing significant improvements over audio-only models in noisy scenarios.
Read paperNews Reporter: A Multi-lingual LLM Framework for Broadcast T.V News
We present a fine-tuned LLM framework for verifiable T.V. news QA pairs, surpassing similar base models and enhancing answer contextualization.
Read paper1SPU: 1-step speech processing unit
1SPU extends ASR with tagged placeholders for semantic events, achieving improved transcription quality on SLUE and SLURP benchmarks.
Read paperE2E spoken entity extraction for virtual agents
This study refines entity extraction directly from speech, optimizing ASR encoders to transcribe only relevant content in virtual agent dialogs.
Read paperCombining pretrained speech and text encoders for continuous spoken language Processing
We introduce a multi-modal model for token-level classification using cross-modal attention, efficient for single GPU training.
Read paperThe Red Hen anonymizer and the red hen protocol for de-identifying audiovisual recordings
The Red Hen Anonymizer enables de-identification of audiovisual data, ensuring privacy while supporting machine learning and research.
Read paper