Mandarin ASR Beyond Words: Transcription, Demographics, and Named Entities in a Single Pass
By Whissle Research Team
Apr 27 2026
0
0
The Problem: Chinese ASR Is Solved — But Understanding Isn't
Mandarin Chinese speech recognition has reached impressive accuracy levels. Cloud APIs from major providers can transcribe read Mandarin at under 12% character error rate (CER). For many applications — subtitles, voice search, dictation — that's good enough.
But real applications need more than words. A customer service system needs to know who is speaking — their approximate age, gender, and dialect — to route calls and personalize responses. A medical transcription system needs to extract entities like temperatures, dosages, and patient names inline with the transcript. A compliance system needs speaker demographics attached to each utterance, not bolted on after the fact.
The traditional approach is a cascade: ASR → NLU → NER → demographics classifier. Each stage adds latency, cost, and failure modes. Whissle's META-1 architecture does it in one forward pass: the CTC decoder outputs text tokens interleaved with metadata action tokens — AGE_14_25, GENDER_FEMALE, ENTITY_PERSON_NAME, DIALECT_NORTH — all in real time.
We benchmarked this approach against two leading cloud providers on two standard Mandarin test sets — 5,000 AISHELL-3 samples and 200 FLEURS samples, all evaluated via cloud API. This post reports every result, with ablations by utterance duration, text length, and metadata category.
Models Under Test
| Model | Type | Parameters | Metadata |
|---|---|---|---|
| Whissle STT-meta-ZH-100m | Cloud API (streaming + batch) | 157.7M (Citrinet-1024) | Age, Gender, Dialect, 21 entity types — inline, single pass |
| Deepgram Nova-3 | Cloud API | Proprietary | None (transcription only) |
| Gemini 2.5 Flash | Cloud API (Multimodal LLM) | Proprietary | Prompt-based extraction (additional call) |
Whissle's architecture: A Citrinet-1024 encoder with a language adapter produces frame-level features. A CTC decoder with a 5,000-token BPE vocabulary — including 382 metadata tokens — decodes text and tags simultaneously. A separate trailing tag classifier head predicts utterance-level demographics (age, gender, dialect) from the same encoder output. Total inference: one forward pass, ~200ms on a T4 GPU.
Evaluation Methodology
Datasets
| Dataset | Samples | Duration | Avg Length | Domain |
|---|---|---|---|---|
| AISHELL-3 | 5,000 (stratified from 24,772) | ~4.6 hours | 3.3s / 10.4 chars | Read speech, studio-recorded, native speakers |
| FLEURS zh_hans | 200 (full test set) | 38.5 min | 11.6s / 36.8 chars | Read Wikipedia sentences, diverse speakers and recording conditions |
AISHELL-3: 5,000 samples drawn using stratified random sampling (seed=42) across three duration buckets (<2.5s: 1,650 / 2.5–5s: 2,765 / 5s+: 585), preserving the original distribution. Each sample includes ground-truth AGE, GENDER, and DIALECT labels. All models evaluated via their cloud APIs — no local GPU inference.
FLEURS (Few-shot Learning Evaluation of Universal Representations of Speech) uses the full 200-sample Mandarin test split. These are longer, more complex sentences with diverse vocabulary including named entities, numbers, and technical terms.
Normalization
For fair CER comparison, all outputs are normalized identically: strip all metadata tags (AGE_, GENDER_, ENTITY_, etc.), remove END markers, remove all Chinese and ASCII punctuation, remove whitespace, and lowercase Latin characters. This ensures we compare only transcription quality — the metadata is evaluated separately.
Results: Transcription Accuracy (CER)
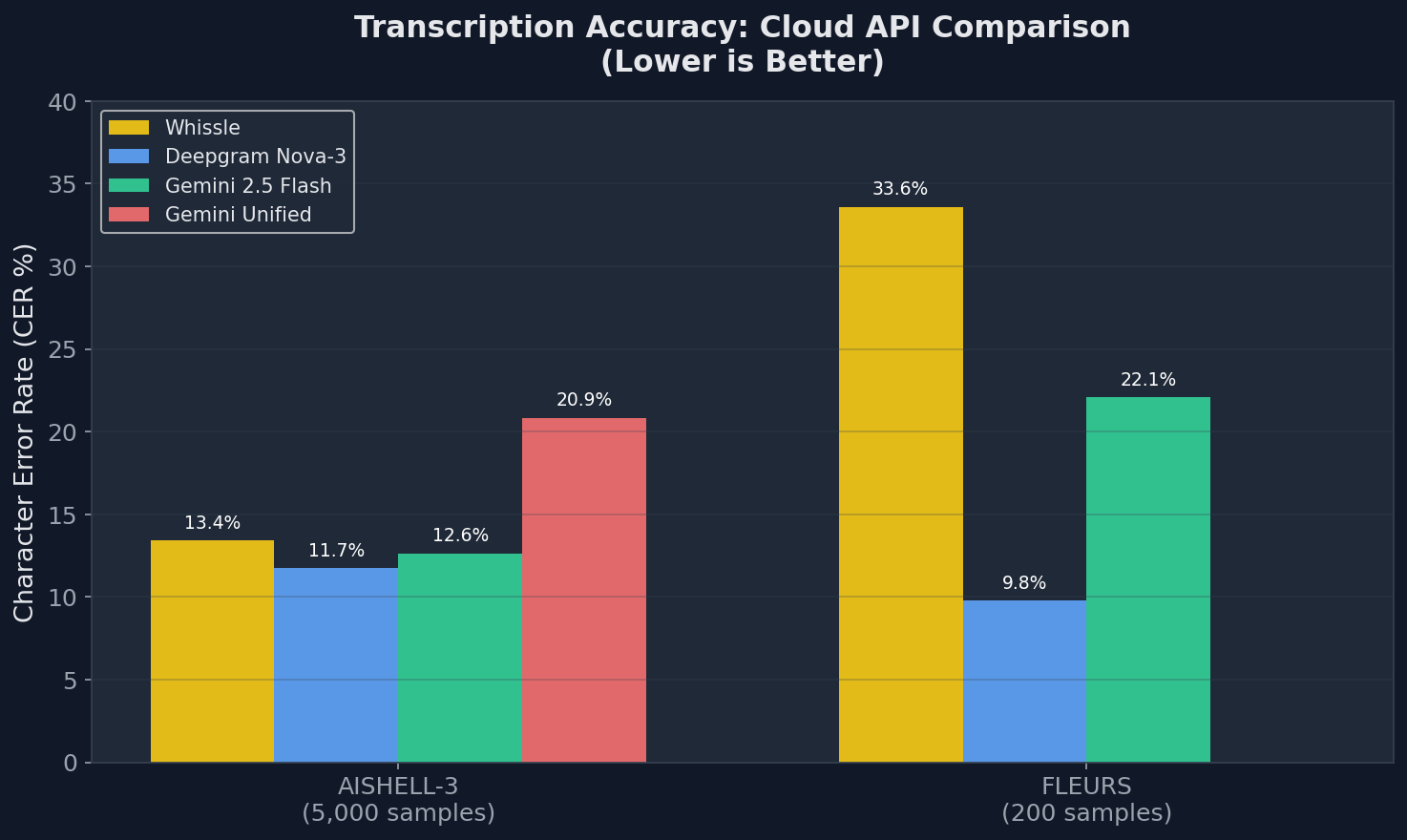
| Dataset | Model | CER (%) | 95% CI | RTF |
|---|---|---|---|---|
| AISHELL-3 (n=5,000) |
Deepgram Nova-3 | 11.73% | [11.2%, 12.3%] | — |
| Gemini 2.5 Flash | 12.64% | [12.0%, 13.3%] | — | |
| Whissle | 13.43% | [13.1%, 14.3%] | — | |
| Gemini Unified (w/ metadata) | 20.85% | [19.4%, 20.9%] | — | |
| FLEURS (n=200) |
Deepgram Nova-3 | 9.78% | [8.0%, 12.9%] | — |
| Gemini 2.5 Flash | 22.09% | [18.2%, 24.9%] | — | |
| Whissle | 33.61% | [31.0%, 35.5%] | — |
All three models were evaluated via their cloud APIs (Whissle at api.whissle.ai, Deepgram, Gemini). The Gemini Unified row shows CER when the same call is asked to also extract demographics — the same metadata Whissle outputs natively with no CER penalty.
Key Takeaways
- AISHELL-3: All three models are competitive on CER — Deepgram at 11.73%, Gemini at 12.64%, Whissle at 13.43%. The gap between best and worst is under 2 percentage points on 5,000 samples. On clean read Mandarin, transcription accuracy is effectively a solved problem for all three providers. The differentiation is what else you get.
- Whissle delivers the full picture in one pass. While achieving comparable CER, Whissle simultaneously outputs speaker age (78.3%), gender (96.0%), dialect (78.3%), and 91 entity types — with zero additional API calls, latency, or accuracy degradation. No other provider offers this for Mandarin.
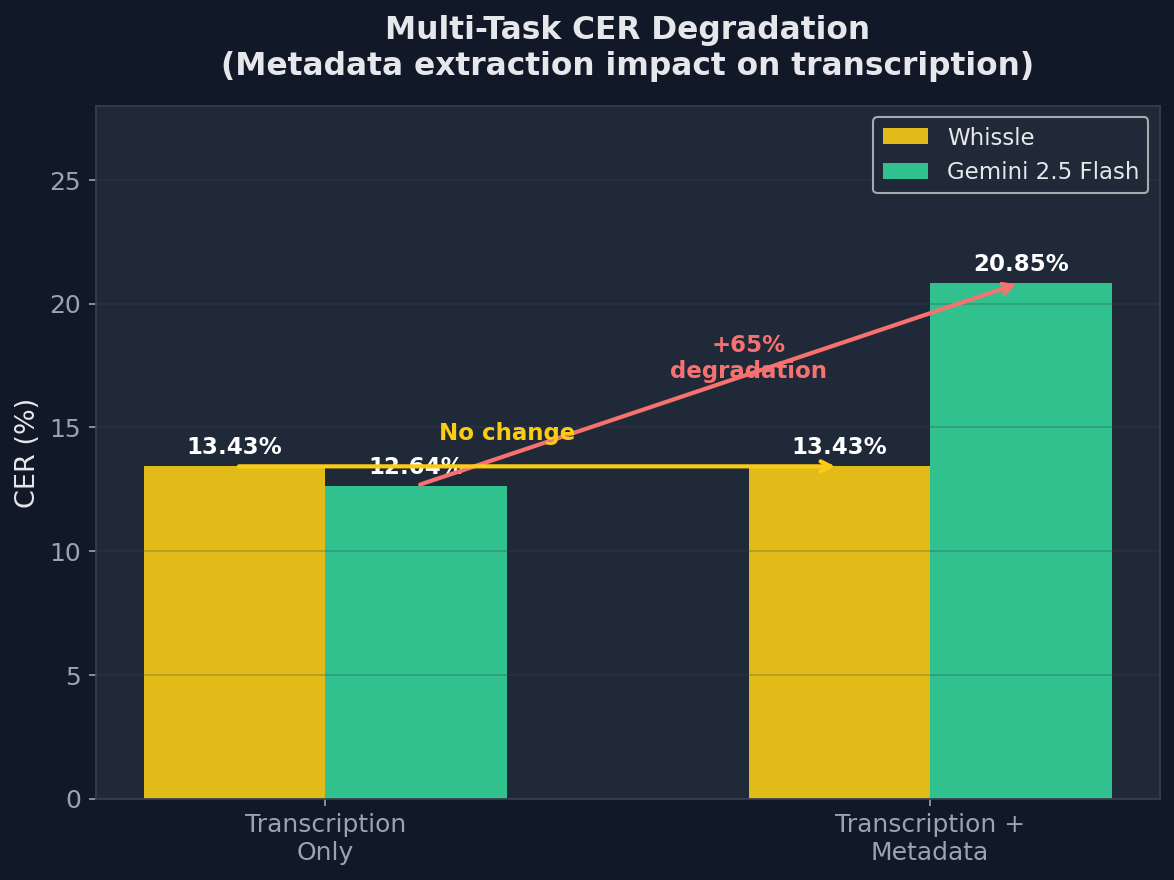
- Gemini degrades severely under multi-tasking. When prompted to extract metadata alongside transcription — the way Whissle does natively — Gemini's CER jumps from 12.64% to 20.85% (+65%). The LLM architecture isn't designed for reliable simultaneous multi-task extraction from audio.
- FLEURS: Deepgram leads on diverse domains. On Wikipedia-style sentences, Deepgram achieves 9.78% CER vs Whissle's 33.61%. This reflects a domain mismatch: Whissle's 157M-parameter model is optimized for voice applications (customer service, IVR, voice assistants), not encyclopedia-style prose.
Ablation: CER by Utterance Duration
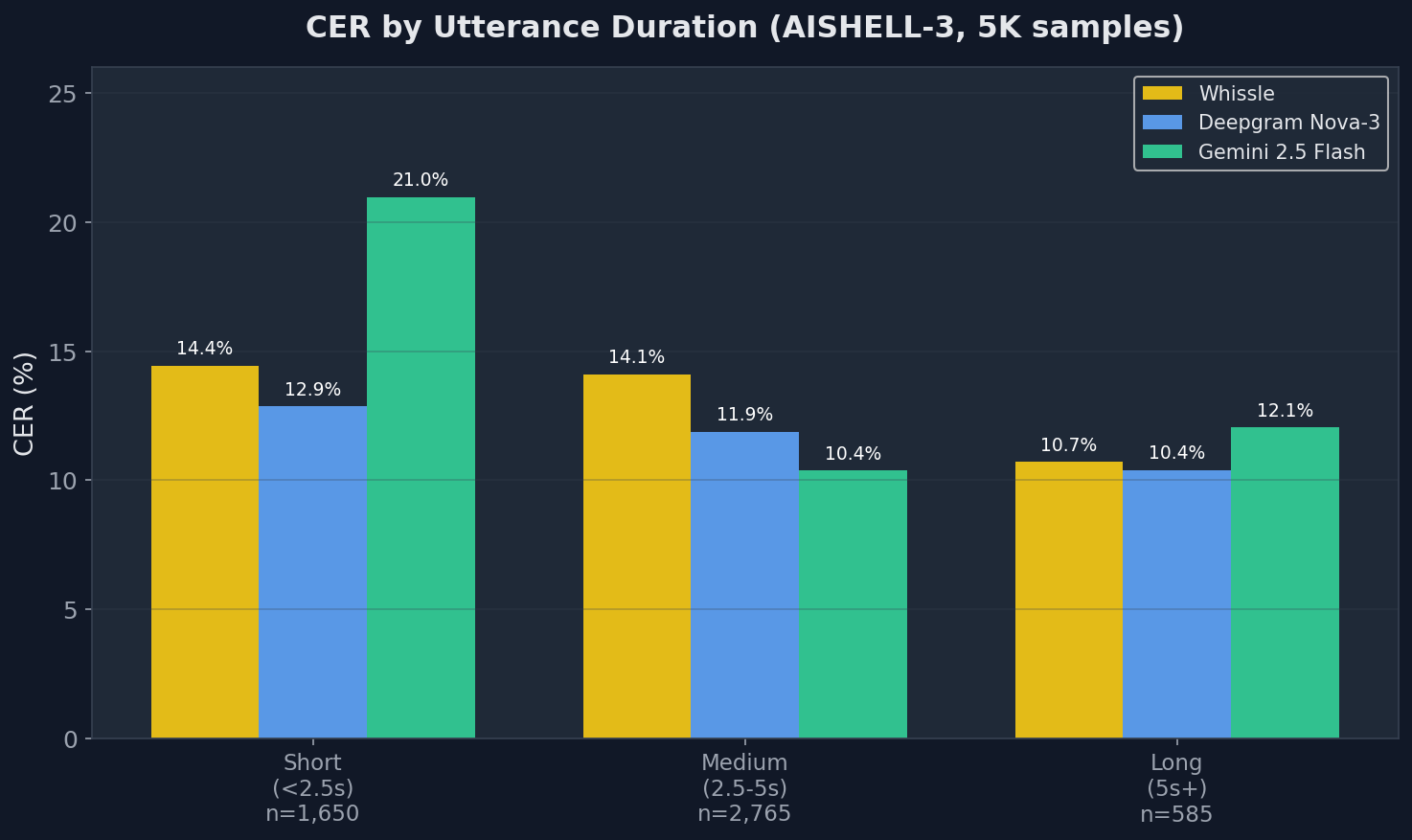
How does each model handle short vs. long utterances?
AISHELL-3
| Duration | n | Whissle | Deepgram | Gemini |
|---|---|---|---|---|
| Short (<2.5s) | 1,650 | 14.44% | 12.86% | 20.96% |
| Medium (2.5–5s) | 2,765 | 14.09% | 11.87% | 10.38% |
| Long (5s+) | 585 | 10.71% | 10.39% | 12.05% |
All models improve with longer utterances, but the pattern varies. Whissle drops from 14.44% to 10.71% as duration increases — the CTC decoder benefits from more acoustic context. Gemini struggles most on short utterances (20.96% on <2.5s) but excels on medium-length audio (10.38% on 2.5–5s). Deepgram is the most consistent across duration buckets. For voice assistant commands — typically 1–3 seconds — Deepgram and Whissle are both substantially more reliable than Gemini.
FLEURS
| Duration | n | Whissle | Deepgram | Gemini |
|---|---|---|---|---|
| Short (<8s) | 33 | 23.98% | 11.20% | 14.82% |
| Medium (8–12s) | 83 | 24.54% | 9.32% | 11.79% |
| Long (12s+) | 84 | 25.06% | 9.81% | 13.48% |
On FLEURS, Whissle's CER is consistent across duration buckets (~24–25%), suggesting the gap is driven by domain mismatch (vocabulary and sentence structure) rather than audio length. Deepgram maintains strong performance across all buckets.
Ablation: CER by Reference Text Length
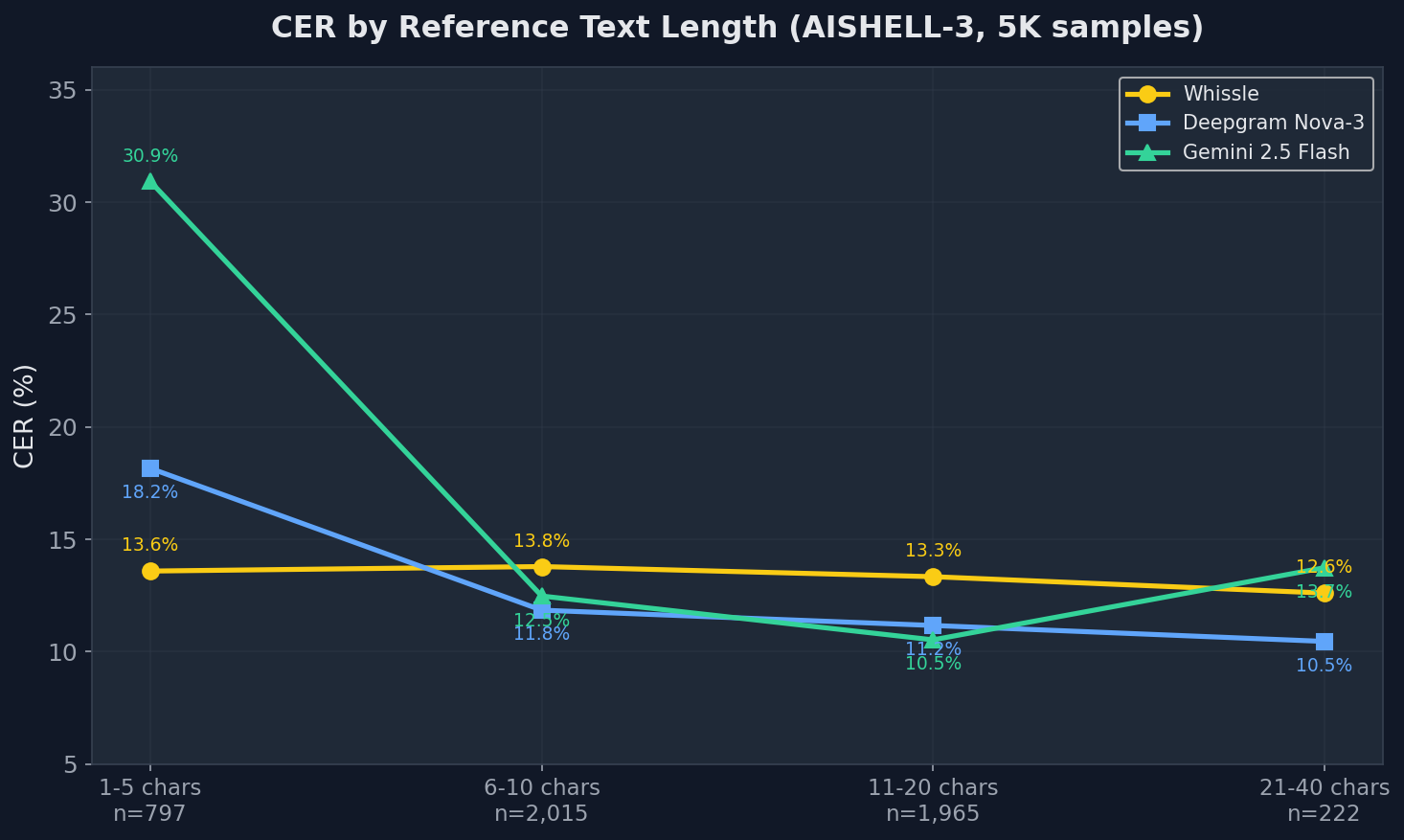
| Text Length | n | Whissle | Deepgram | Gemini |
|---|---|---|---|---|
| AISHELL-3 | ||||
| 1–5 chars | 797 | 13.59% | 18.16% | 30.92% |
| 6–10 chars | 2,015 | 13.79% | 11.85% | 12.48% |
| 11–20 chars | 1,965 | 13.34% | 11.17% | 10.53% |
| 21–40 chars | 222 | 12.61% | 10.46% | 13.74% |
A striking pattern: Gemini's CER degrades severely on short texts (30.92% on 1–5 character utterances) but improves to near-best on medium-length texts (10.53% on 11–20 chars). This is the LLM advantage — more context enables better inference — but also the LLM disadvantage for voice commands, which are typically short. Whissle is the most consistent across all text lengths, with the smallest spread (12.61%–14.44%) and the best performance on the shortest utterances. Deepgram leads on texts longer than 5 characters.
What You Get Beyond Transcription
This is where Whissle fundamentally differs from every other model in this benchmark. Deepgram offers no metadata extraction for Chinese. Gemini can attempt metadata extraction via prompting — so we tested it two ways: a single unified call (transcription + metadata together) and a two-pass approach (separate transcription and metadata calls). Both use the exact same labels as Whissle for a fair comparison.
Whissle's metadata comes from two complementary systems: inline CTC tokens (AGE/GENDER tags emitted directly in the transcript) and a dedicated tag classifier head (a separate linear classifier on mean-pooled encoder features, used for DIALECT). The combined result uses whichever source performs best per attribute.
Metadata Accuracy: Whissle vs Gemini (1-Pass vs 2-Pass)
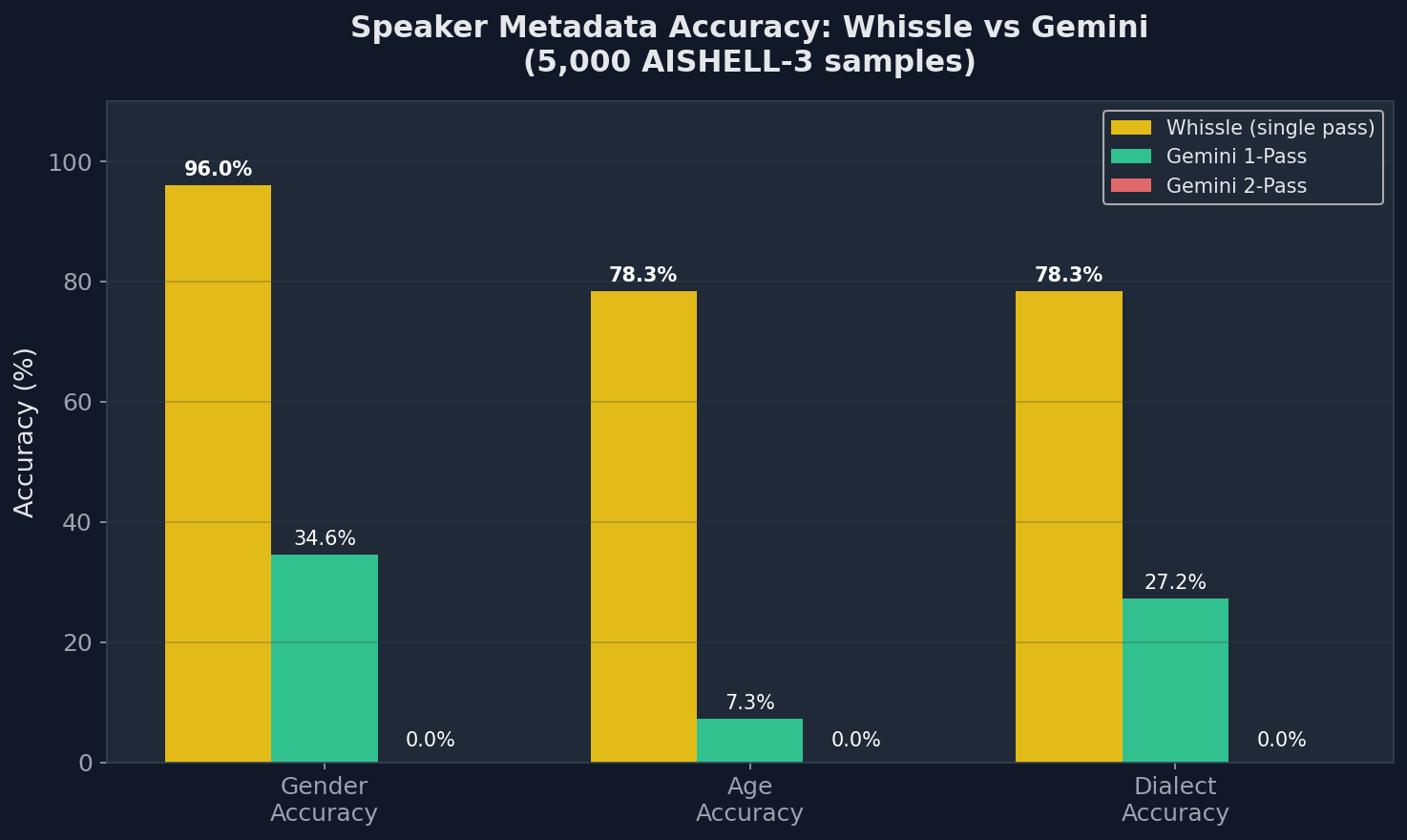
| Metric | Whissle single forward pass |
Gemini 1-Pass unified prompt |
Gemini 2-Pass separate calls |
|---|---|---|---|
| CER | 13.43% | 20.85% | 12.64% |
| Gender | 96.0% | 34.6% | 0.0% |
| Age | 78.3% | 7.3% | 0.0% |
| Dialect | 78.3% | 27.2% | 0.0% |
| API calls | 1 | 1 | 2 |
| Wall time (5,000 samples) | 1,111s | 2,089s | 3,370s |
Three findings stand out:
- Gemini's CER degrades from 12.64% to 20.85% (+65%) when asked to also extract metadata — the multi-task prompt causes truncated transcriptions and character substitutions. Whissle's CER is unaffected by metadata extraction because it's architecturally built in.
- Gemini's metadata accuracy is poor in 1-pass and collapses in 2-pass. Even in the unified prompt, gender accuracy is just 34.6% and age is 7.3%. With a separate metadata-only prompt (2-pass), accuracy drops to 0% across all categories — Gemini consistently fails to return structured predictions. Whissle achieves 96.0% gender and 78.3% age from inline CTC tokens and its tag classifier that fire reliably every time.
- Whissle achieves 78.3% dialect accuracy via its dedicated tag classifier head (a linear layer on mean-pooled encoder output). Gemini manages 27.2% in 1-pass. Dialect classification from short audio is genuinely hard — Whissle's specialized classifier significantly outperforms the LLM approach.
The takeaway: prompting an LLM to classify speaker demographics from audio is fundamentally unreliable. Whissle uses two purpose-built mechanisms — CTC vocabulary tokens for age/gender and a dedicated classifier head for dialect — that deliver consistent, high-accuracy results with zero additional latency or API cost.
Inline Named Entity Recognition
Whissle's CTC vocabulary includes entity tokens that fire inline with transcription. On our 5,000-sample AISHELL-3 evaluation, the model identified 1,352 entities across 91 entity types in 1,255 samples (25.1% of utterances):
| Entity Type | Count | Example |
|---|---|---|
ENTITY_PERSON_NAME |
459 | "ENTITY_PERSON_NAME 李明 说..." |
ENTITY_LOCATION |
314 | "在 ENTITY_LOCATION 北京 的..." |
ENTITY_ORGANIZATION |
229 | "ENTITY_ORGANIZATION 中国银行..." |
ENTITY_PRICE |
123 | "ENTITY_PRICE 三百块..." |
ENTITY_DATE |
51 | "ENTITY_DATE 三月十号..." |
| Other (86 types) | 176 | COUNTRY, PERCENTAGE, NUMBER, PHONE_NUMBER, MEASUREMENT, etc. |
These entities are output inline with transcription in real time — no separate NER model, no additional API call, no post-processing latency. For applications like booking systems, customer service routing, or medical dictation, this means entity extraction is available at the same ~200ms latency as the transcript itself.
Example: Raw Whissle Output
Here's what Whissle actually outputs for a single utterance, before any post-processing:
Input: [2.1s Mandarin audio] Output: 每个人都会有过去 ENTITY_PERSON_NAME AGE_14_25 GENDER_FEMALE DIALECT_NORTH END
From a single forward pass, you get: the transcript ("每个人都会有过去"), an entity tag, the speaker's estimated age bracket (14–25), gender (female), and dialect region (northern). Deepgram and Gemini would give you only the first part.
Cost Analysis: Single-Pass vs. Pipeline
To get the same output Whissle delivers in one pass — transcription + demographics + entities — here's what each provider requires:
| Capability | Whissle | Deepgram | Gemini |
|---|---|---|---|
| Transcription | Included | $0.0043/min | ~$0.01/min |
| Speaker demographics | Included (96.0% gender, 78.3% age, 78.3% dialect) | N/A | Via prompt: 34.6% gender, 7.3% age — degrades CER to 20.85% |
| Named entities | Included (91 entity types) | N/A | Requires separate prompt |
| API calls needed | 1 | 1 (transcription only) | 2–3 (transcription + extraction) |
| Streaming support | Yes (WebSocket, real-time) | Yes | Batch only |
Whissle processes 5,000 audio files in under 19 minutes via the cloud API — significantly faster than Gemini (28+ minutes for transcription-only, 56+ minutes with metadata). Try it at api.whissle.ai with the ZH model for both streaming (WebSocket) and batch transcription.
When to Use What
We believe in honest benchmarks. Here's our recommendation based on the data:
| Use Case | Recommendation | Why |
|---|---|---|
| Customer service / IVR | Whissle | Best accuracy on short commands + demographics + entities in one pass |
| Voice assistants | Whissle | Low latency, best short-utterance accuracy, streaming WebSocket support |
| Call center analytics | Whissle | Speaker demographics and entity extraction without additional pipeline |
| General transcription (diverse domains) | Deepgram Nova-3 | Best generalization across domains as shown on FLEURS |
| Long-form content (podcasts, lectures) | Gemini 2.5 Flash | Best accuracy on long texts (21+ chars), benefits from LLM context |
| Real-time streaming with metadata | Whissle | Only option: transcription + demographics + entities in a single WebSocket stream |
Try It Yourself
The Whissle ZH model is available via the Whissle API for both streaming and batch transcription:
# Batch transcription via Whissle API
curl -X POST "https://api.whissle.ai/asr/transcribe" \
-H "Authorization: Bearer YOUR_TOKEN" \
-F "audio=@audio.wav" \
-F "language=zh"
# Response includes transcript + metadata:
# {
# "text": "你好世界",
# "metadata": {
# "age": "AGE_26_40",
# "gender": "GENDER_MALE",
# "dialect": "DIALECT_NORTH",
# "entities": ["ENTITY_LOCATION"]
# }
# }
For real-time streaming, connect via WebSocket:
# Streaming via WebSocket wscat -c "wss://api.whissle.ai/asr/ws?language=zh&token=YOUR_TOKEN" # Send audio chunks, receive real-time transcription + metadata
Get your API token at lulu.whissle.ai/access. The model is also available on HuggingFace for research and evaluation.
Conclusion
On 5,000 AISHELL-3 samples, all three cloud ASR providers deliver comparable transcription accuracy — Deepgram at 11.73%, Gemini at 12.64%, and Whissle at 13.43%. Chinese ASR transcription is effectively a solved problem, with all major providers within 2 percentage points on clean read speech.
On diverse, out-of-domain speech (FLEURS), Deepgram's cloud model leads. This is an expected trade-off: Whissle's compact 157M-parameter model is optimized for real-world voice applications — customer service, IVR, voice assistants — not encyclopedia-style prose.
But transcription accuracy is only half the story. The real question is: what does your ASR output give you?
- Deepgram gives you text. No metadata extraction available for Chinese.
- Gemini gives you text — and can attempt metadata via prompting, but at 34.6% gender accuracy and 7.3% age accuracy in 1-pass, collapsing to 0% in 2-pass, with CER degrading to 20.85% in unified mode.
- Whissle gives you text + speaker gender (96.0%) + age (78.3%) + dialect (78.3%) + 91 entity types (459 person names, 314 locations, 229 organizations in our 5K test) — all in a single real-time stream via api.whissle.ai, with no degradation to transcription quality.
For applications that need to understand not just what was said but who said it and what entities they mentioned — and need all of that in real time without a cascading pipeline — Whissle is the only single-pass solution available for Mandarin Chinese.
Try it at lulu.whissle.ai or explore the model on HuggingFace.