Gujlish META-ASR: A Bilingual English-Gujarati Speech Model with Built-in Speaker Profiling
By Whissle Research Team
May 16 2026
0
0

Code-switching — seamlessly mixing two languages within a single conversation — is the norm for hundreds of millions of speakers worldwide. In Gujarat alone, most educated speakers effortlessly blend Gujarati and English in everyday conversation. Yet the vast majority of ASR systems treat each language in isolation, forcing developers to choose a single language model or build complex switching pipelines.
What if a single 95-million-parameter model could transcribe both languages, detect the speaker's age and gender, classify their emotion, identify their intent, and extract named entities — all in 2.6 milliseconds?
We trained exactly that. Today we're open-sourcing this model on HuggingFace and sharing the full benchmark results across 26,669 test samples spanning 50 hours of audio from 7 diverse datasets.
Why Gujlish?
"Gujlish" is our shorthand for the English-Gujarati code-switching pattern common in western India. A typical sentence might be: "Meeting tomorrow છે, please confirm કરો" (Meeting is tomorrow, please confirm). Traditional ASR systems fail on these inputs because they're trained on monolingual data and can't handle script-switching mid-sentence.
Our approach handles this natively: the model's vocabulary includes both Latin and Gujarati script characters, so it can output mixed-script transcriptions without any language detection step.
Architecture
The model is based on CLSRIL-23, a wav2vec2-base model pre-trained by IIT Madras on 23 Indian languages. We fine-tuned it with CTC loss on a bilingual corpus with inline meta-tag tokens.
| Architecture | Wav2Vec2ForCTC (HuggingFace Transformers) |
| Base Model | CLSRIL-23 (wav2vec2-base, 23 Indian languages) |
| Parameters | 95M |
| Vocabulary | 795 tokens (Latin + Gujarati chars + meta-tags) |
| Input | Raw 16kHz waveform |
| Output | Transcript + AGE + GENDER + EMOTION + INTENT + ENTITY tags |
| Feature Extractor | Frozen (7 CNN layers) |
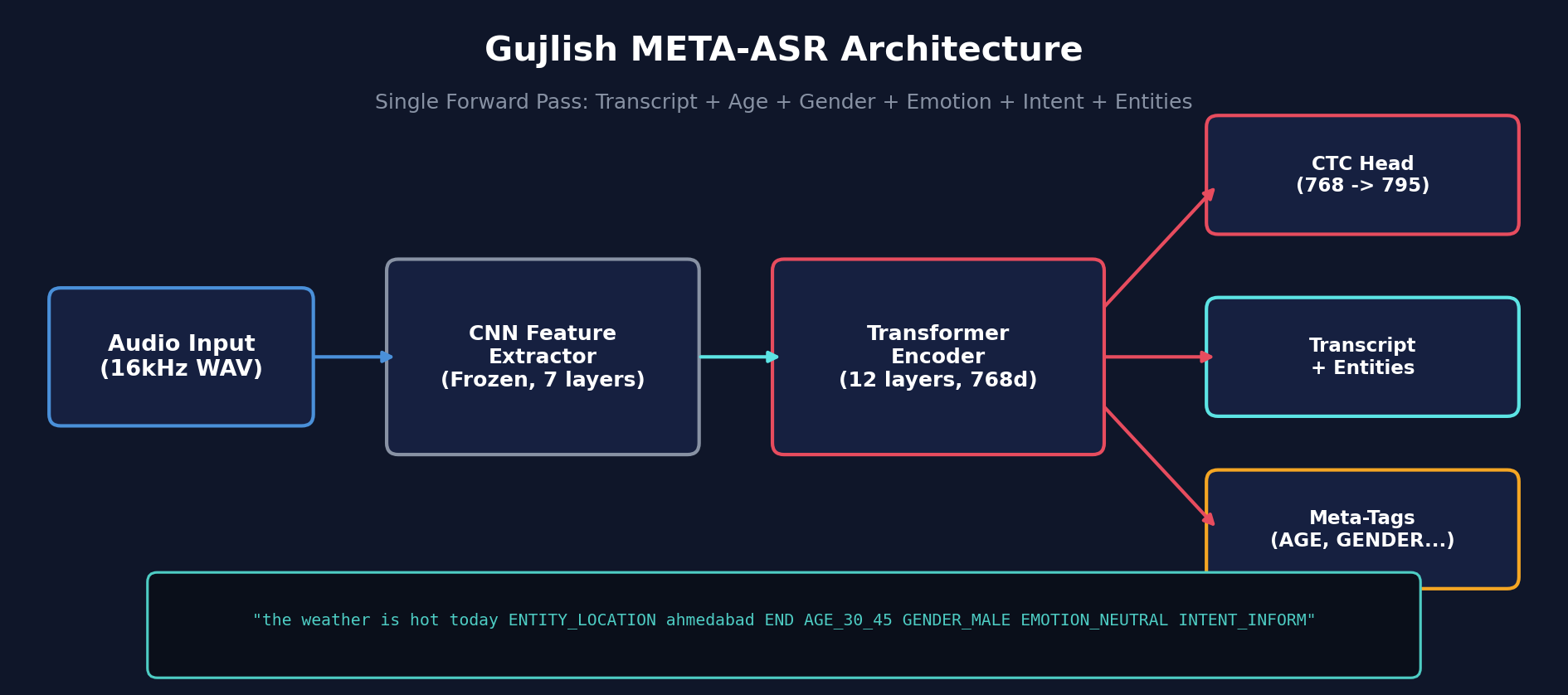
Meta-Tag Output
Unlike traditional ASR that outputs plain text, our model produces enriched transcriptions with inline metadata. A single forward pass outputs:
the weather in ENTITY_LOCATION ahmedabad END is very hot today AGE_30_45 GENDER_MALE EMOTION_NEUTRAL INTENT_INFORM
Training Data
We curated a bilingual corpus of 525,500 training samples (~977 hours) from multiple sources:
| Source | Language | Samples | Share |
|---|---|---|---|
| CommonVoice 17, Internal recordings | English | 284,278 | 54.1% |
| IndicVoices, Kathbath, CommonVoice, FLEURS | Gujarati | 165,222 | 31.4% |
| Short command utterances | English | 76,000 | 14.5% |
| Total | 525,500 | ~977h | |
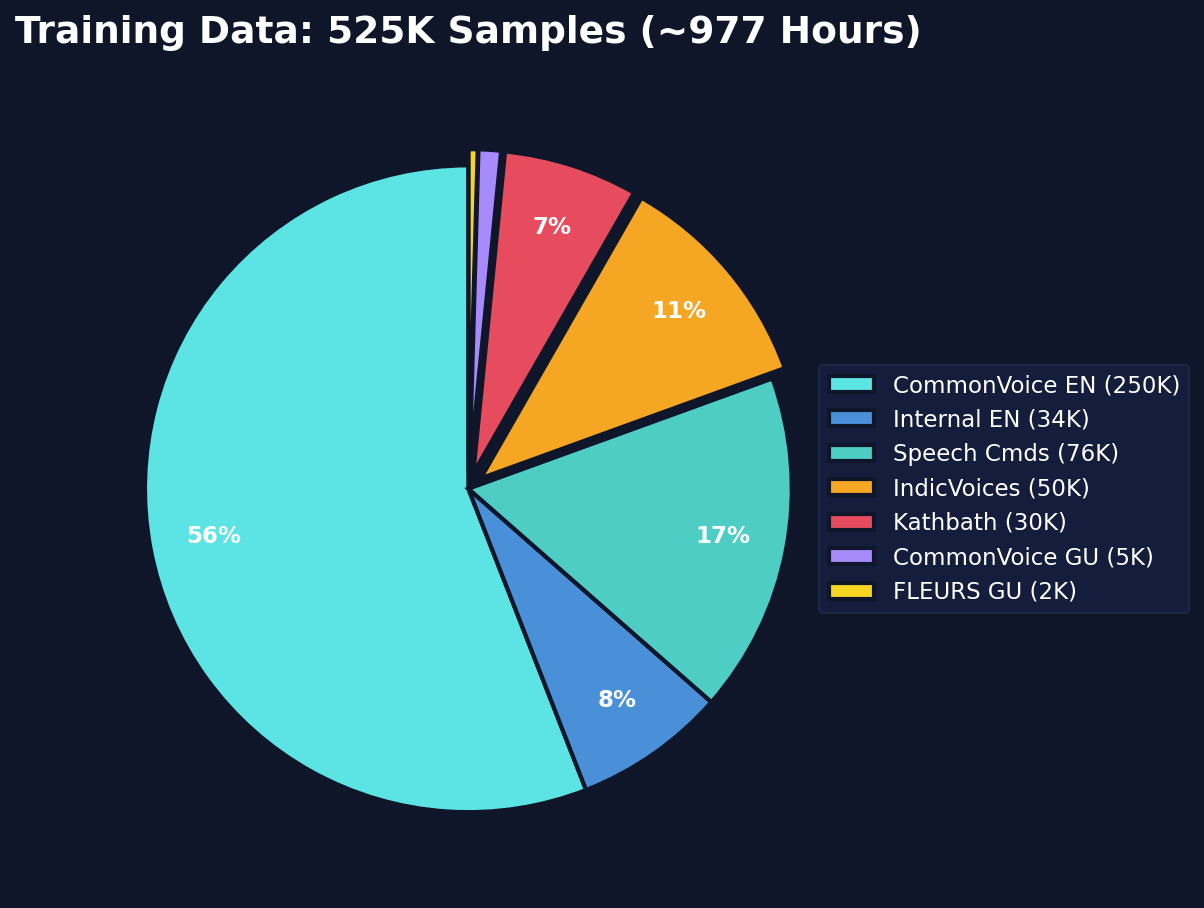
All samples were annotated with meta-tags (AGE, GENDER, EMOTION, INTENT, ENTITY) using our automated annotation pipeline powered by Gemini. The model was trained for 100K steps with aggressive 70% noise augmentation (SNR range -40 to -10 dB) to build robustness against real-world recording conditions. The best checkpoint was selected at step 65,000 based on validation WER.
The English-Gujarati data ratio (69% vs 31%) was intentional — English data is more abundant and diverse, while we maximized coverage of available Gujarati corpora. As we'll see in the results, this imbalance directly impacts per-language performance.
Full Benchmark Results
We evaluated the model on the complete held-out validation set: 26,669 samples spanning 49.6 hours of audio. Zero failed audio loads — every sample was processed successfully.
Combined Results (26,669 samples, 49.6 hours)
| Metric | Value |
|---|---|
| Clean WER | 20.74% |
| Clean CER | 11.55% |
| Age Accuracy | 83.2% |
| Gender Accuracy | 98.6% |
| Emotion Accuracy | 80.2% |
| Intent Accuracy | 81.5% |
| Entity F1 | 22.3% |
| Avg Latency | 2.6ms |
| Real-Time Factor | 0.0004x |
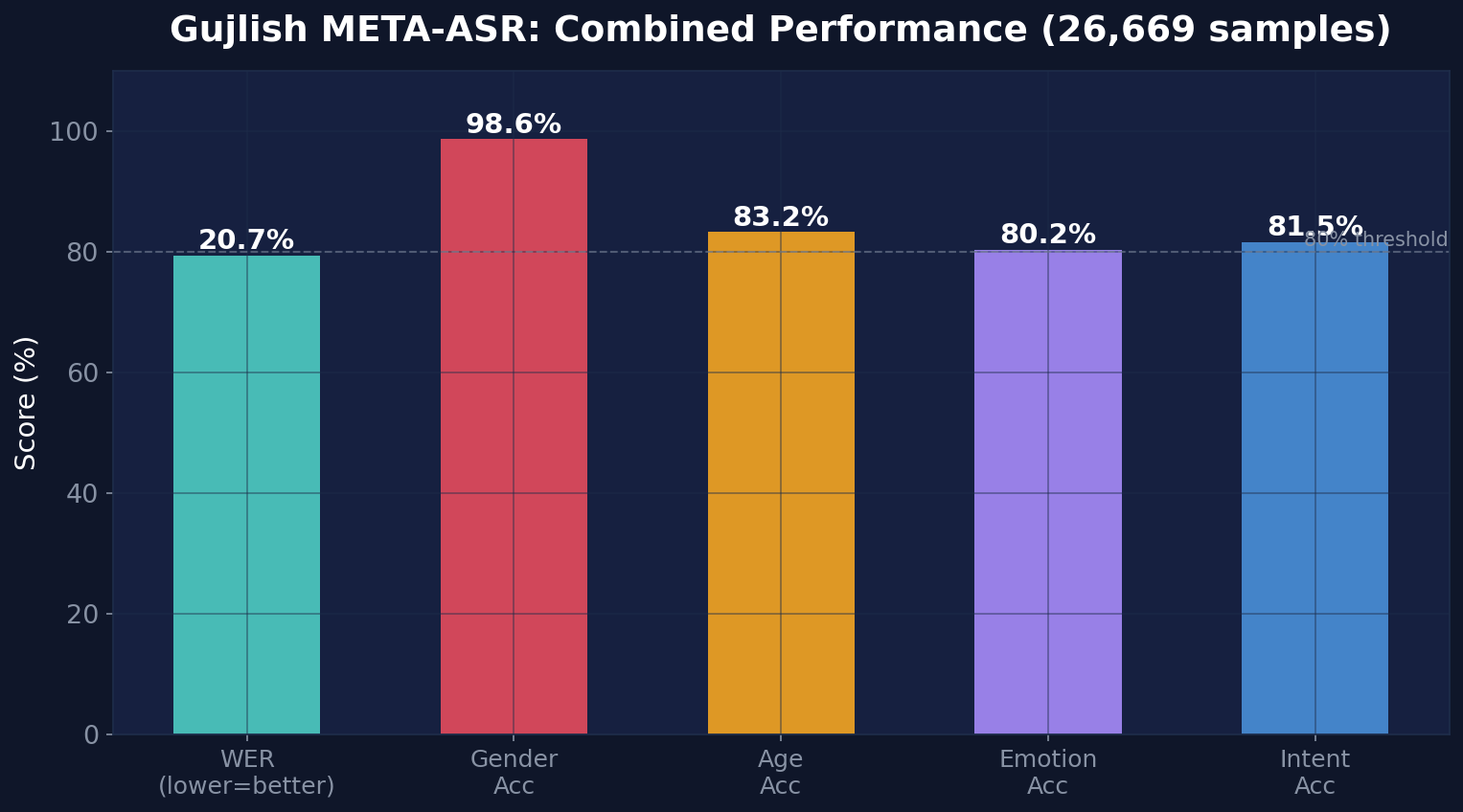
Every metric except entity extraction crosses the 80% threshold. Gender classification is near-perfect at 98.6%, and the model achieves a real-time factor of 0.0004x — meaning it processes audio 2,500 times faster than real-time on an A100 GPU.
By Language
| Metric | English (18,962 / 35h) | Gujarati (7,707 / 14.6h) |
|---|---|---|
| Clean WER | 15.41% | 38.16% |
| Age Accuracy | 80.2% | 89.2% |
| Gender Accuracy | 98.3% | 99.4% |
| Emotion Accuracy | 79.4% | 81.9% |
| Intent Accuracy | 80.9% | 82.7% |
| Entity F1 | 31.0% | 13.5% |
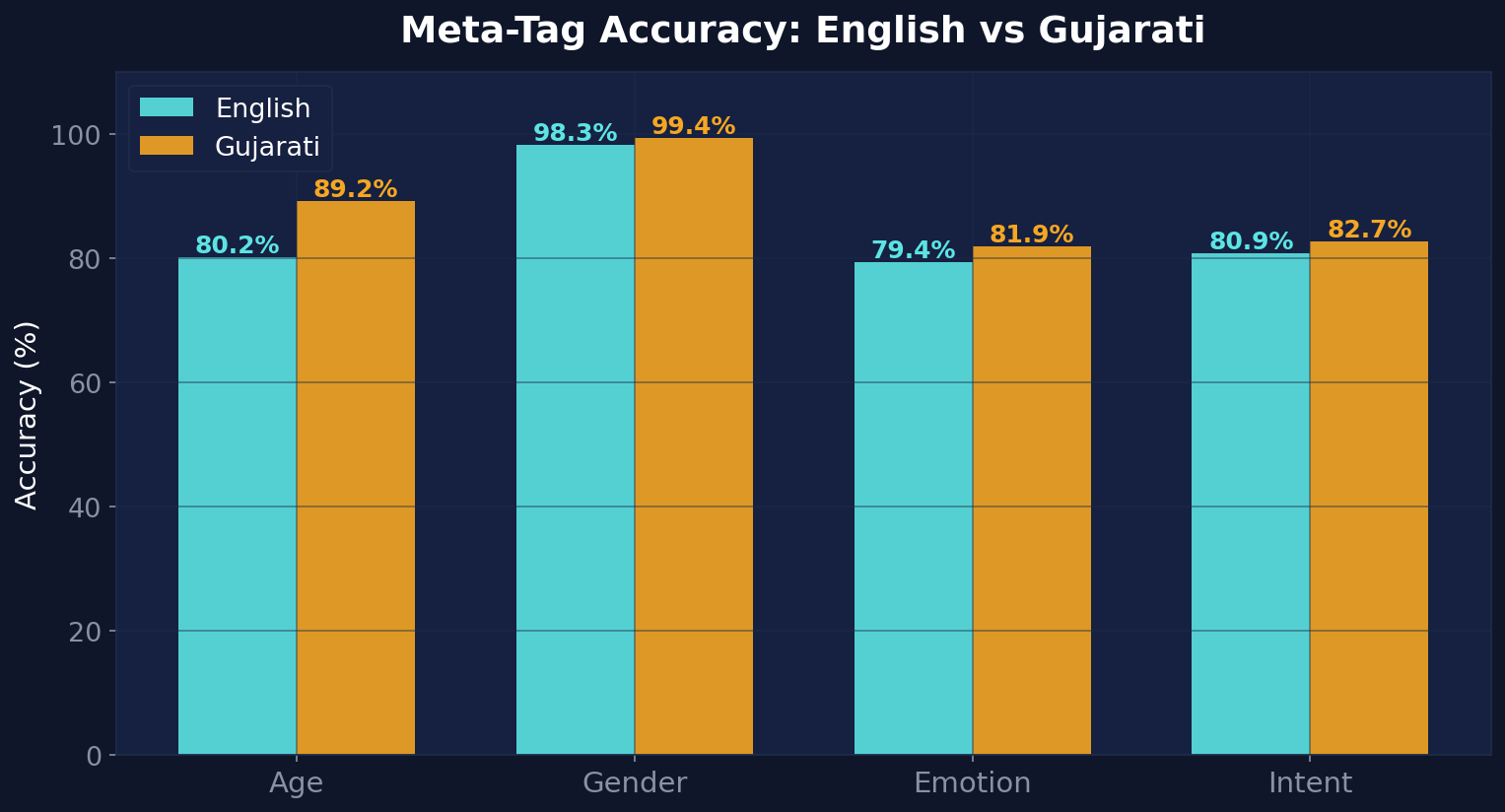
A surprising finding: Gujarati outperforms English on every meta-tag category. Despite having lower ASR accuracy, the Gujarati audio sources appear to have more consistent speaker demographics and clearer emotional expression, making classification easier. Gender accuracy hits 99.4% for Gujarati — essentially flawless.
By Source Dataset
| Dataset | Samples | Duration | Clean WER | AGE | GENDER | EMOTION | INTENT |
|---|---|---|---|---|---|---|---|
| en_people | 8,462 | 24.6h | 12.67% | 76.5% | 98.7% | 85.0% | 71.9% |
| cv_english | 6,500 | 9.3h | 26.90% | 85.1% | 97.8% | 72.1% | 92.7% |
| speech_commands | 4,000 | 1.1h | 3.33% | — | — | — | — |
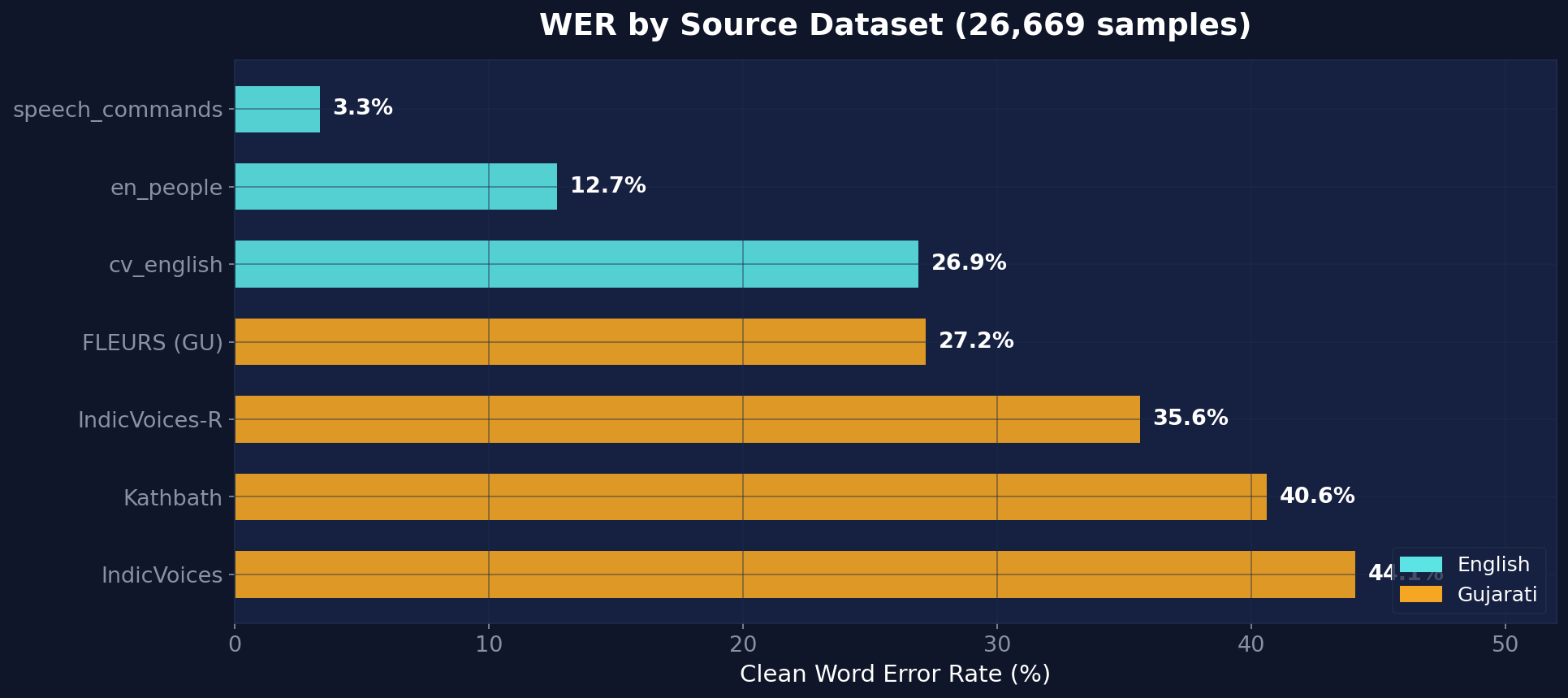
The chart reveals a clear story: the model excels on speech commands (3.3% WER — near-perfect keyword recognition) and conversational English (12.7% WER). Performance degrades as we move to Gujarati datasets, with a wide 27-44% WER range that reflects the diversity of recording conditions across Gujarati corpora.
Gujarati — Per-Dataset Breakdown
The combined Gujarati result (38.16% WER) masks significant variation across the four constituent datasets. Here's the full breakdown across 7,707 Gujarati samples (14.6 hours):
| Dataset | Samples | Duration | Clean WER | CER | AGE | GENDER | EMOTION | INTENT |
|---|---|---|---|---|---|---|---|---|
| FLEURS | 432 | 1.2h | 27.18% | 7.03% | — | — | — | — |
| IndicVoices-R | 662 | 1.3h | 35.61% | 32.47% | 82.6% | 97.3% | 84.0% | 83.8% |
| Kathbath | 3,343 | 5.4h | 40.60% | 32.53% | 100% | 99.9% | 81.5% | 91.1% |
| IndicVoices | 3,270 | 6.6h | 44.08% | 35.81% | 79.4% | 99.3% | 81.8% | 74.0% |
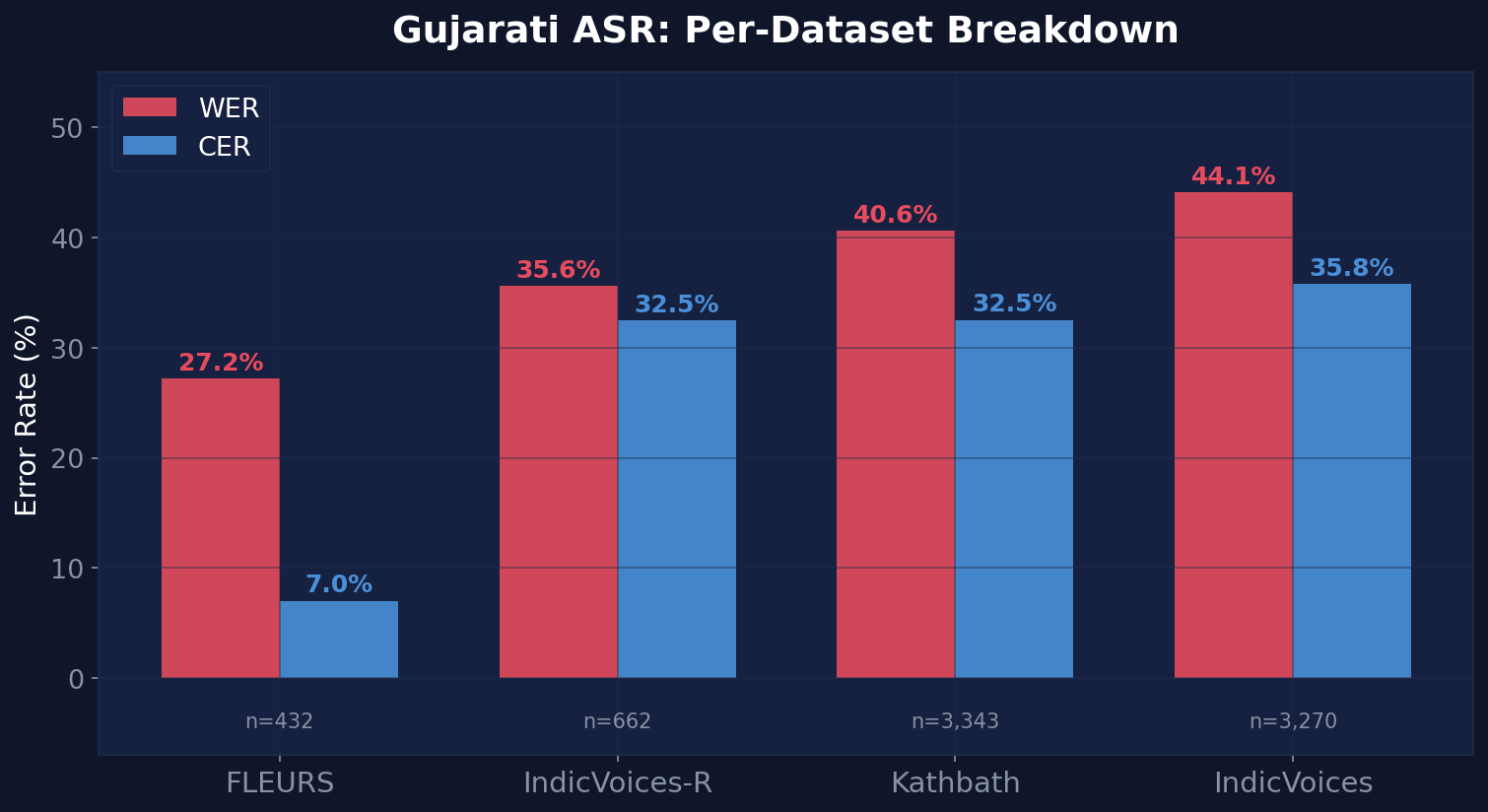
The chart tells a nuanced story about what drives WER in Gujarati:
- FLEURS (Google's benchmark) achieves the best Gujarati WER at 27.18% with an exceptionally low 7.03% CER — this is clean, read speech from professional recordings. The massive gap between WER and CER suggests the model gets most characters right but misses word boundaries.
- IndicVoices-R (AI4Bharat's curated set) lands at 35.6% WER with strong meta-tag performance — 82.6% age and 97.3% gender accuracy across 662 samples.
- Kathbath stands out with perfect 100% age accuracy and 99.9% gender accuracy across 3,343 samples, suggesting highly consistent speaker demographics in the dataset. At 40.6% WER, the model struggles more with Kathbath's longer, more complex utterances.
- IndicVoices is the hardest at 44.1% WER — it contains the most diverse, spontaneous recordings with varied recording conditions, accents, and background noise. With 3,270 samples over 6.6 hours, it's also the largest Gujarati subset.
Key Takeaways
Conversational English is strong
On our en_people dataset — real-world conversational recordings averaging 10+ seconds per utterance — the model achieves 12.67% clean WER. This is the model's sweet spot: natural, long-form speech with varied speakers and topics.
Gender detection is near-perfect
98.6% accuracy across 22,236 evaluated samples. This is remarkable because gender is inferred purely from the audio signal — no text-based heuristics. The model learned robust acoustic features for gender classification as a byproduct of CTC training.
All metadata is "free"
The 95M-parameter model runs at 2.6ms per utterance on A100 (RTF 0.0004x). Age, gender, emotion, intent, and entities are all extracted in the same forward pass that produces the transcript — no separate classification models, no pipeline overhead, no additional latency.
Gujarati performance varies by dataset
At 38% clean WER, Gujarati transcription trails English significantly. This reflects the training data imbalance (31% Gujarati vs 69% English) and the inherent difficulty of Gujarati script recognition with limited training data. We're actively expanding the Gujarati training corpus with more IndicVoices and Kathbath data.
Open Source
The model is available on HuggingFace under the Apache 2.0 license:
The repo includes:
model.safetensors— The fine-tuned weights (362 MB)config.json— HuggingFace Transformers-compatible architecture configvocab.json— 795-token vocabulary (Latin + Gujarati + meta-tags)infer_wav2vec2_gujlish.py— Standalone inference script with batch processing
Usage
pip install torch torchaudio transformers python infer_wav2vec2_gujlish.py \ --model WhissleAI/speech-tagger_gujlish_wav2vec2_meta \ --audio your_audio.wav
What's Next
This is the first in a family of bilingual META-ASR models we're releasing. Coming soon:
- Hinglish (Hindi + English): Currently in production with 15.4% clean WER, already deployed to our live API
- Mandarin + English: Also in production, optimized for business conversations
- More Indic languages: Bengali, Marathi, Tamil, and Punjabi models in the pipeline
If you're building voice-first applications that need more than just transcription — whether it's call analytics, voice assistants, or meeting intelligence — reach out. We'd love to hear what you're working on.