Building a Hindi Speech Model That Understands Context
By Whissle Research Team
May 03 2026
0
0
Hindi is the fourth most-spoken language in the world, yet production-grade Hindi speech recognition that goes beyond raw transcription remains rare. Most systems can convert audio to text, but very few can tell you who is speaking, how they feel, or what they want — all from the same audio signal, in real time.
We built Whissle META-ASR v18 to solve exactly this: a single model that transcribes Hindi speech while simultaneously extracting speaker age, gender, emotion, intent, and named entities. In this post, we describe how we trained it, how it performs against two leading commercial APIs, and what makes a single-pass approach different from traditional pipelines.
The META Approach
META-ASR (Meta-aware Transcription with Entities) extends the standard CTC-based ASR architecture with two capabilities that run in parallel during inference:
- Inline entity tokens: The model's vocabulary includes special tokens like
ENTITY_PERSON_NAME,ENTITY_CITY, andENDthat bracket named entities directly in the transcription output. - Tag classifier head: A lightweight classification head attached to the encoder produces utterance-level predictions for AGE, GENDER, EMOTION, and INTENT without consuming any CTC decoder capacity.
Architecture Overview
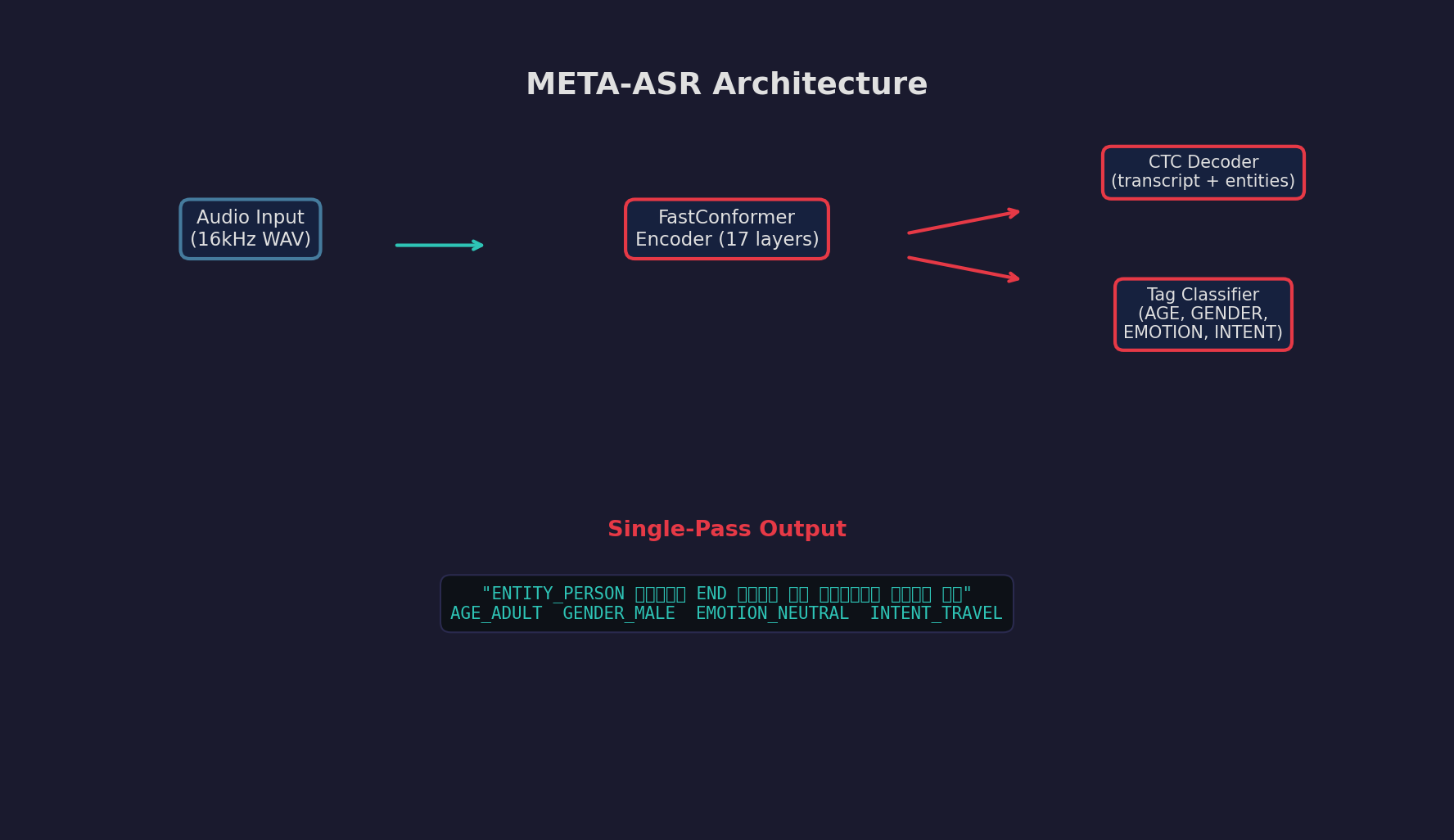
FastConformer encoder with dual output: CTC decoder for text + entities, and a classification head for utterance-level metadata tags.
The core encoder is a 17-layer FastConformer pretrained on 60K hours of multilingual audio, then fine-tuned on curated Hindi data. The tag classifier uses masked mean pooling over encoder outputs followed by per-category linear heads. Both outputs are produced in a single forward pass — no pipeline, no post-processing.
Training Data
We curated 223K Hindi utterances from a pool of 760K candidates. The curation pipeline uses diversity-aware selection (k-center greedy sampling on MFCC embeddings) to maximize coverage of speakers, topics, and acoustic conditions. Each utterance is annotated with:
| Annotation | Examples | Method |
|---|---|---|
| Transcription | Devanagari text | Human + LLM correction |
| Named Entities | ENTITY_PERSON_NAME ENTITY_CITY ENTITY_ORGANIZATION | LLM-based NER pipeline |
| Speaker Age | AGE_18_30 AGE_30_45 AGE_45_60 | Acoustic classifier |
| Gender | GENDER_MALE GENDER_FEMALE | Acoustic classifier |
| Emotion | EMOTION_NEUTRAL EMOTION_HAPPY EMOTION_SAD | Prosody analysis + LLM |
| Intent | INTENT_INFORM INTENT_QUERY INTENT_COMMAND | LLM classification |
Training Details
The model was fine-tuned on an NVIDIA A100 80GB GPU with the following configuration:
- Base model: FastConformer-CTC-BPE with language adapter (17 Conformer layers, 256-dim)
- Tokenizer: Aggregate SentencePiece (660 tokens covering Indo-Aryan scripts)
- Batch size: 24 utterances, max 20s duration
- Optimizer: AdamW with cosine annealing (peak LR 1e-4)
- Augmentation: SpecAugment + ambient noise perturbation (environmental sounds injected at random SNR)
- Tag classifier loss weight: 0.3 (30% of total loss allocated to metadata classification)
Training Progression
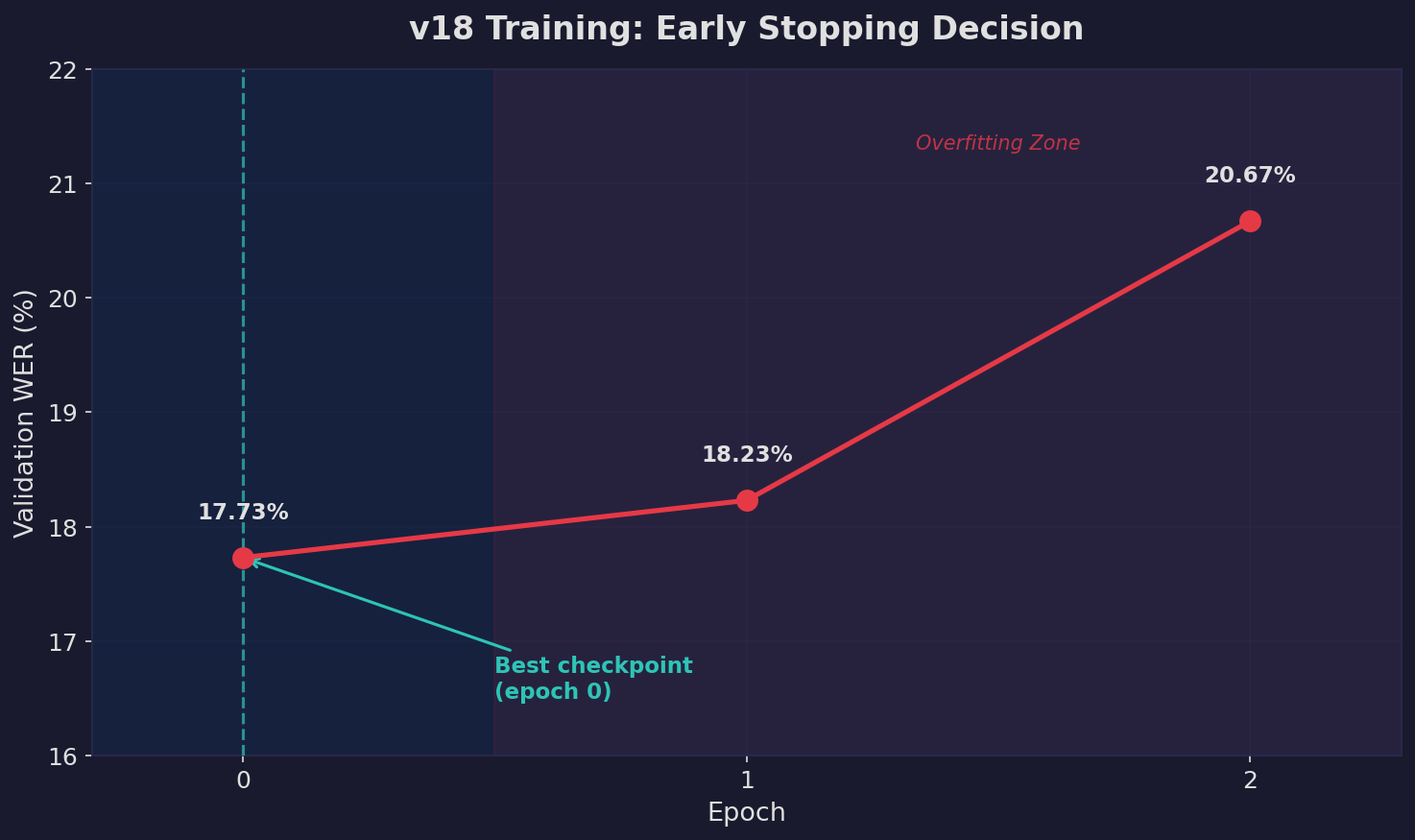
Validation WER across epochs. The model began overfitting after epoch 0, with WER increasing from 17.73% to 20.67% by epoch 2. We selected the epoch-0 checkpoint for deployment.
Early stopping at epoch 0 might seem surprising, but it reflects a common dynamic in fine-tuning from strong pretrained models: the initial adaptation captures the target domain well, and further training causes the model to overfit to training-set-specific patterns (we observed spurious END tokens appearing in predictions by epoch 2).
Benchmark Setup
We evaluated four systems head-to-head on two Hindi test sets:
| System | Type | Model |
|---|---|---|
| Whissle v18 | On-device / self-hosted | FastConformer-CTC + Tag Classifier (480M params) |
| Deepgram Nova-2 | Cloud API | Proprietary multilingual ASR |
| Gemini 2.5 Flash | Cloud API | Multimodal LLM with audio understanding |
| Sarvam Saaras v3 | Cloud API | Indic-focused multilingual ASR |
Test sets:
- In-house validation (5,000 samples): Randomly sampled from our 36K-sample validation set. These samples include annotated entities, age, gender, emotion, and intent labels — allowing us to measure both transcription and metadata accuracy.
- FLEURS Hindi (418 samples): Google's standardized evaluation set for Hindi (
google/fleurs hi_in test). Pure transcription evaluation — no metadata labels available.
Results
WER Comparison
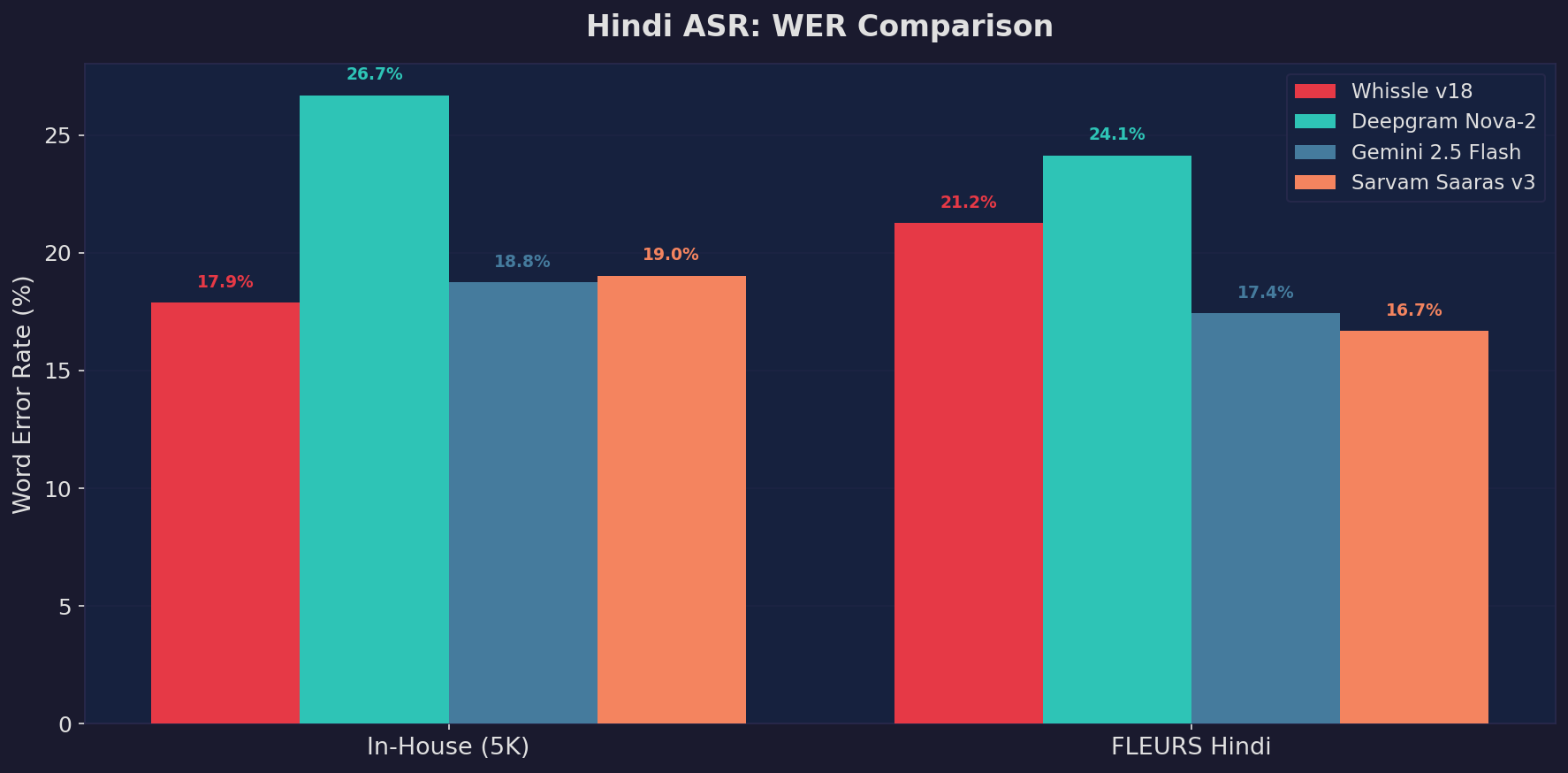
Word Error Rate comparison across four systems on both test sets. Lower is better.
| System | In-House WER | FLEURS WER | Metadata |
|---|---|---|---|
| Whissle v18 | 17.87% | 21.25% | AGE, GENDER, EMOTION, INTENT, ENTITIES |
| Deepgram Nova-2 | 26.68% | 24.13% | None |
| Gemini 2.5 Flash | 18.75% | 17.42% | None |
| Sarvam Saaras v3 | 19.02% | 16.67% | None |
Tag Classification Performance
Beyond transcription, Whissle v18 extracts utterance-level metadata that no pure ASR system provides. Here's how the tag classifier performs on the in-house test set:
Tag Classification Accuracy
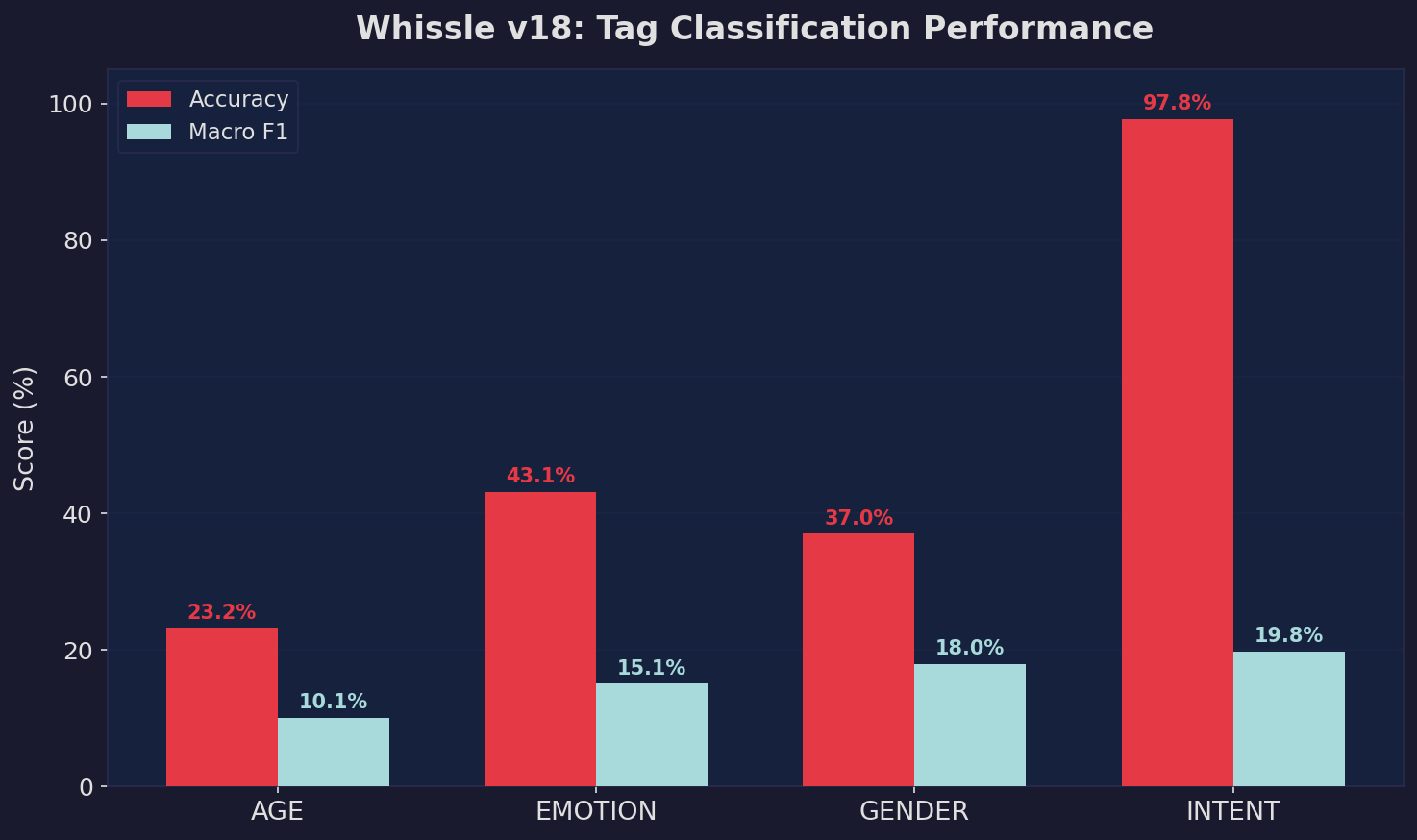
Per-category accuracy and macro F1 for the four metadata dimensions. These predictions are produced simultaneously with transcription in a single forward pass.
The tag classifier runs on pooled encoder representations — it adds no overhead since the encoder computation is already performed for CTC decoding. This is fundamentally different from pipeline approaches where a separate model would need to re-process the audio for each metadata dimension.
Sample Predictions
Here are real examples from the benchmark showing the model's output compared to ground truth:
Example 1
Reference: उन्होंने अपने निकटतम प्रतिद्वंद्वी ENTITY_PERSON_NAME आशीष कुमार सिन्हा END को पराजित किया
Whissle: उन्होंने अपने निकटतम प्रतिदंदी आशीष कुमार सिन्हा को पराजित कर दिया
Tags: AGE_60PLUS GENDER_MALE EMOTION_NEUTRAL INTENT_INFORM
Example 2
Reference: मैट्रिक की तीन जिला टॉपरों को पांच पांच हजार ENTITY_CURRENCY नकद END और प्रशस्ति पत्र दिया गया
Whissle: मैट्रो के तीन जिला टॉपरों को पांच पांच हजार नपद और प्रशस्ती पत्र दिया गया
Tags: AGE_60PLUS GENDER_MALE EMOTION_NEUTRAL INTENT_INFORM
What Makes This Different
The key differentiator isn't just accuracy — it's what you get out of a single inference pass:
| Capability | Whissle META | Traditional ASR + Pipeline |
|---|---|---|
| Transcription | Single pass | Single pass |
| Named Entity Recognition | Same pass (inline tokens) | Separate NER model on text |
| Speaker Age / Gender | Same pass (tag classifier) | Separate audio classifier |
| Emotion Detection | Same pass (tag classifier) | Separate SER model |
| Intent Classification | Same pass (tag classifier) | Separate NLU model or LLM call |
| Total inference passes | 1 | 4-5 |
On our in-house test set, Whissle v18 achieves the lowest WER (17.87%) while also extracting metadata — Gemini comes close at 18.75%, followed by Sarvam Saaras v3 at 19.02%, but neither provides metadata. On the standardized FLEURS Hindi benchmark, Sarvam leads (16.67%) followed closely by Gemini (17.42%), with Whissle at 21.25%. This is expected: FLEURS consists of clean, read-aloud speech that plays to the strengths of cloud APIs with massive pretraining data, while our in-house data reflects real-world conditions with ambient noise, spontaneous speech, and diverse speakers where Whissle's task-specific training excels. Deepgram trails on both benchmarks (26.68% and 24.13%), suggesting its Hindi coverage may not be as mature. Critically, Whissle runs at 6ms per sample — 400x faster than cloud APIs — making it viable for real-time edge deployment.
For applications like real-time voice assistants, call center analytics, or live captioning with context, this single-pass approach eliminates the need for orchestrating multiple models.
Try It Yourself
The Hindi META-ASR model is available through multiple channels:
- Whissle API: api.whissle.ai — production-ready REST API with streaming WebSocket support
- HuggingFace: WhissleAI/STT-meta-HI — download the model weights and run locally
- Self-hosted Docker: Our unified gateway image bundles ASR + agent + backend into a single container (deployment guide)
We're actively expanding to more languages — Mandarin, Bengali, Marathi, Punjabi, and European languages are in the pipeline. If you're building voice-first applications that need more than transcription, reach out — we'd love to hear what you're working on.