Catching Lies Without Watching: Privacy-Preserving Multimodal Deception Detection
By Whissle Research Team
Jun 20 2026
0
0
Abstract
Frontier multimodal models can guess whether a person is lying from a testimony video. To do so, they stream that person's raw face and voice to a third-party model. We ask whether the heavy media is needed at all. On the Real-life Trial Deception dataset (121 courtroom clips), Whissle's on-device speech and vision stack extracts a compact digest: transcript, emotion, age, gender, intent distributions, a deception-intent filter, fluency and rhythm, per-frame facial behaviour, and prosody — about 250 numbers per clip. Under speaker-independent evaluation, we report three findings. A small classifier on this digest reaches AUC 0.741, matching Gemini 2.5 Pro on full video (0.749). Handing the digest to a frontier LLM reaches AUC 0.755 with Claude Opus 4.8 at 7.8× fewer input tokens, with no media leaving the device. The reported 75% accuracy is a speaker-leakage artefact. We release code and experiments.
Code & data: github.com/WhissleAI/lie_detection_binary
Introduction
When a witness takes the stand, every pause, glance, and word is scrutinised for deception. Automating that judgement is an old and fraught dream. The polygraph is unreliable and easily countered. Human observers barely beat chance [1]. Multimodal large language models (LLMs) have revived the dream. Give a model the video, ask "is this person lying?", and it does meaningfully better than chance [6].
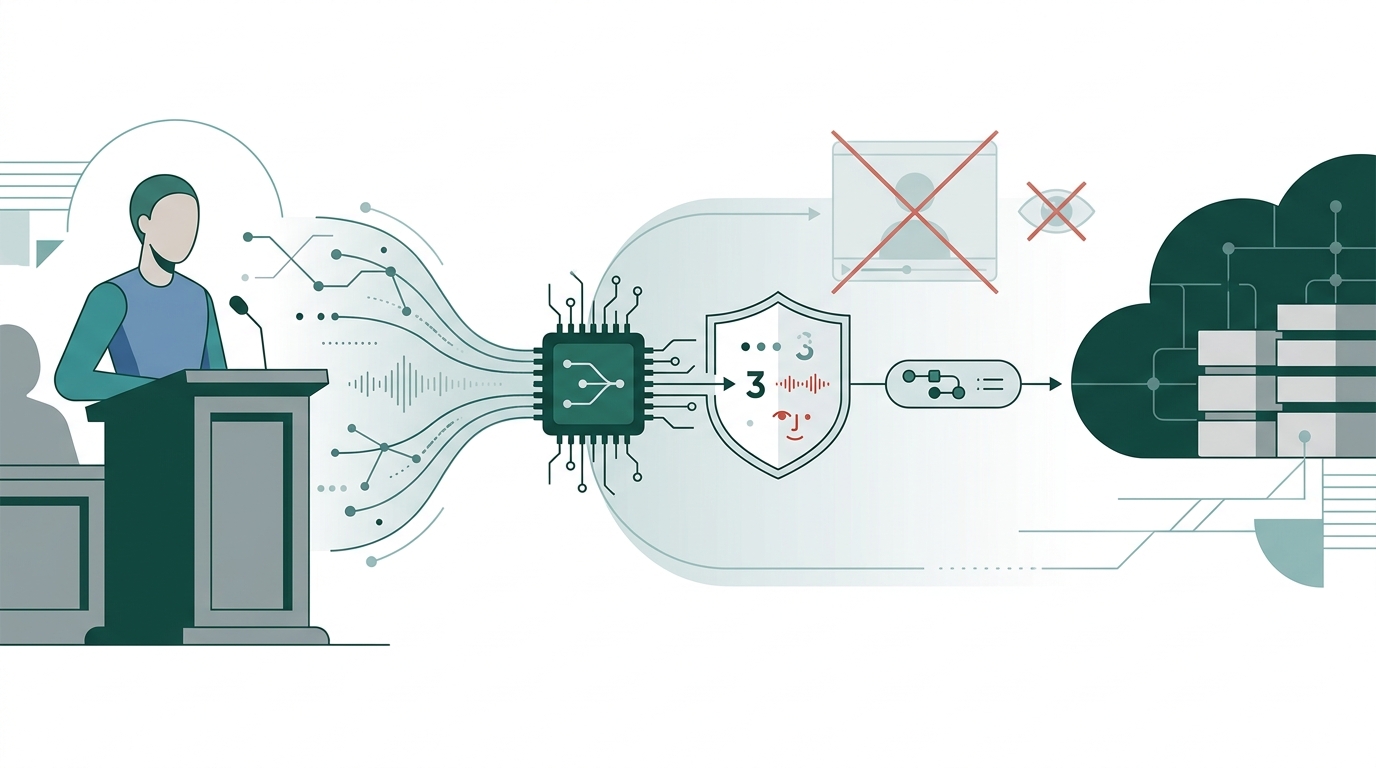
This convenience hides a cost. Sending raw video of a defendant, patient, or customer exposes their face and voice to a third party. Video is token-heavy, so the request is expensive. The verdict is opaque and hard to contest. In legal, clinical, and enterprise settings, "upload the suspect's video" is a non-starter.
This paper asks a narrow question. How much signal survives if we never send the video — only a compact, interpretable digest extracted on-device? We study this on the Real-life Trial Deception dataset [1] and make four contributions.
- A privacy-preserving multimodal pipeline. Whissle's on-device STT and vision stack turns each clip into ~250 interpretable verbal, paralinguistic, and visual features, with no raw media leaving the box (see Method).
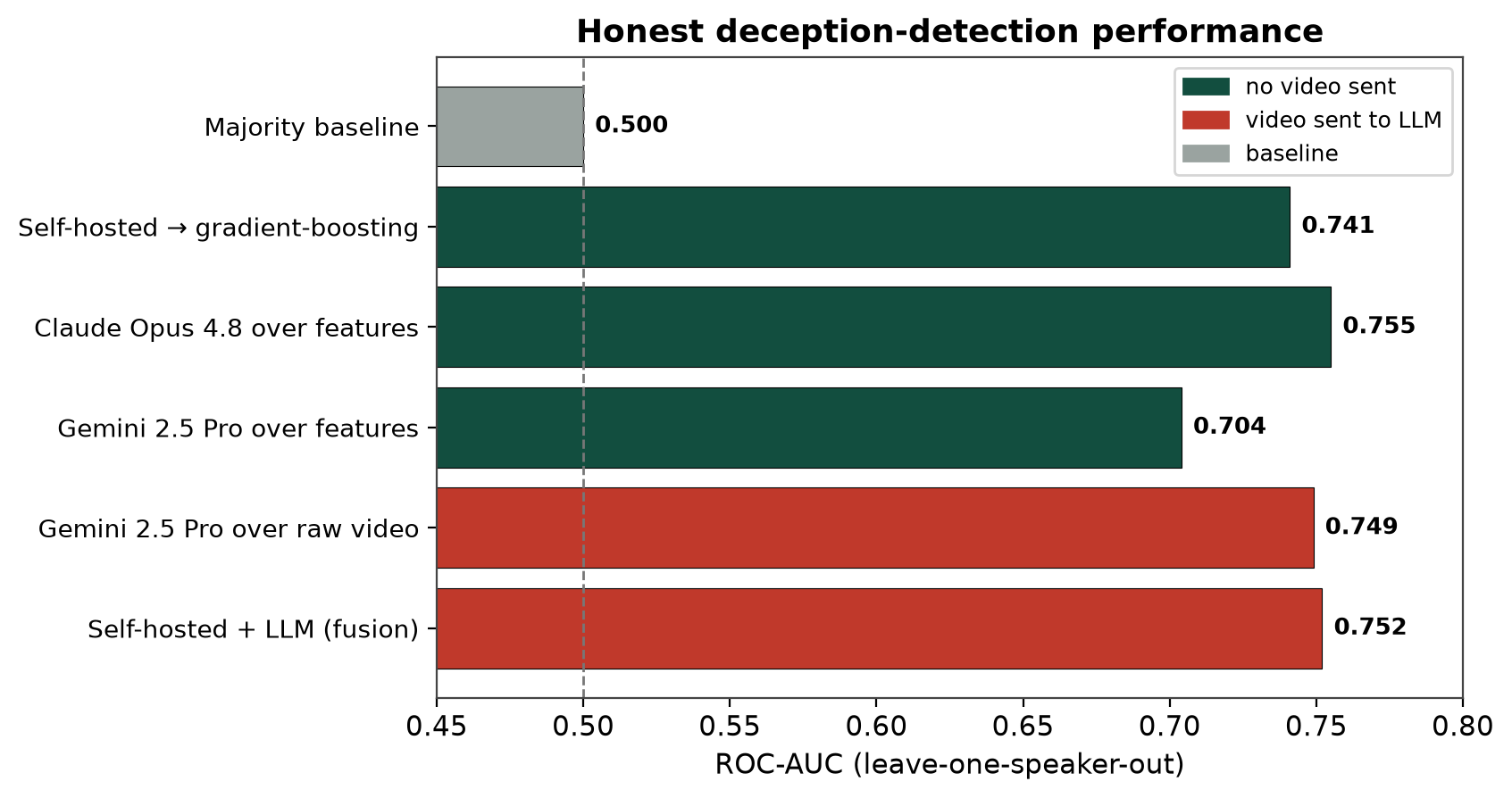
- A clean four-way comparison across two axes — trained vs. zero-shot and with-LLM vs. without-LLM — under speaker-independent evaluation (see Experiments). A trained classifier on our digest (AUC 0.741) matches an LLM watching raw video (0.749). An LLM judging our digest reaches 0.755, beating the video model.
- A cost analysis showing the digest uses 7.8× fewer LLM input tokens than raw video (see Cost Analysis). It is cheaper, faster, private, and more accurate.
- An honesty audit. We show the literature's 75% is a leave-one-video-out number inflated by speaker leakage. We quantify a demographic confound and report the speaker-independent result (see Ablation Studies).
Related Work
The 2015 baseline. Pérez-Rosas et al. introduced the Real-life Trial Deception dataset and the first multimodal system on it [1]. Earlier work used lab or crowdsourced lies — mock crimes, the "werewolf" game [4] — where unmotivated subjects generalise poorly to real stakes. They instead used 121 public courtroom clips labelled from verdicts and exonerations [1]. Their system fused transcript n-grams with 40 hand-coded MUMIN gesture features for 75.2% accuracy — but from a single best decision-tree cell; a random forest scored only 50.4% [1].
Verbal and non-verbal cues. Two older strands feed this work. Text-only methods use n-grams and lexicons like LIWC: liars use fewer first-person and exclusive words and more negative emotion [2], each weak alone but useful together. Behavioural methods use physiological signals or hand-coded facial and gesture annotations [3]; frowns, raised brows, and head turns track deception, and deceivers blink and shake their heads less [1, 3]. These cues are noisy — and in 2015 were labelled by hand with knowledge of each clip, not extracted automatically [1].
The present: LLMs over video. Multimodal LLMs now judge deception from video zero-shot [6], and new datasets pair audio with video [5]. They are powerful but expensive and privacy-invasive — and, as we show, no better than reasoning over a compact digest.
The gap we address. Three limits of the 2015 work persist. Its non-verbal features are hand-annotated, not automatic — we extract them on-device. Its leave-one-video-out evaluation leaks speaker identity and inflates accuracy — we evaluate speaker-independently. And neither it nor video LLMs count token cost — we measure it directly.
Dataset
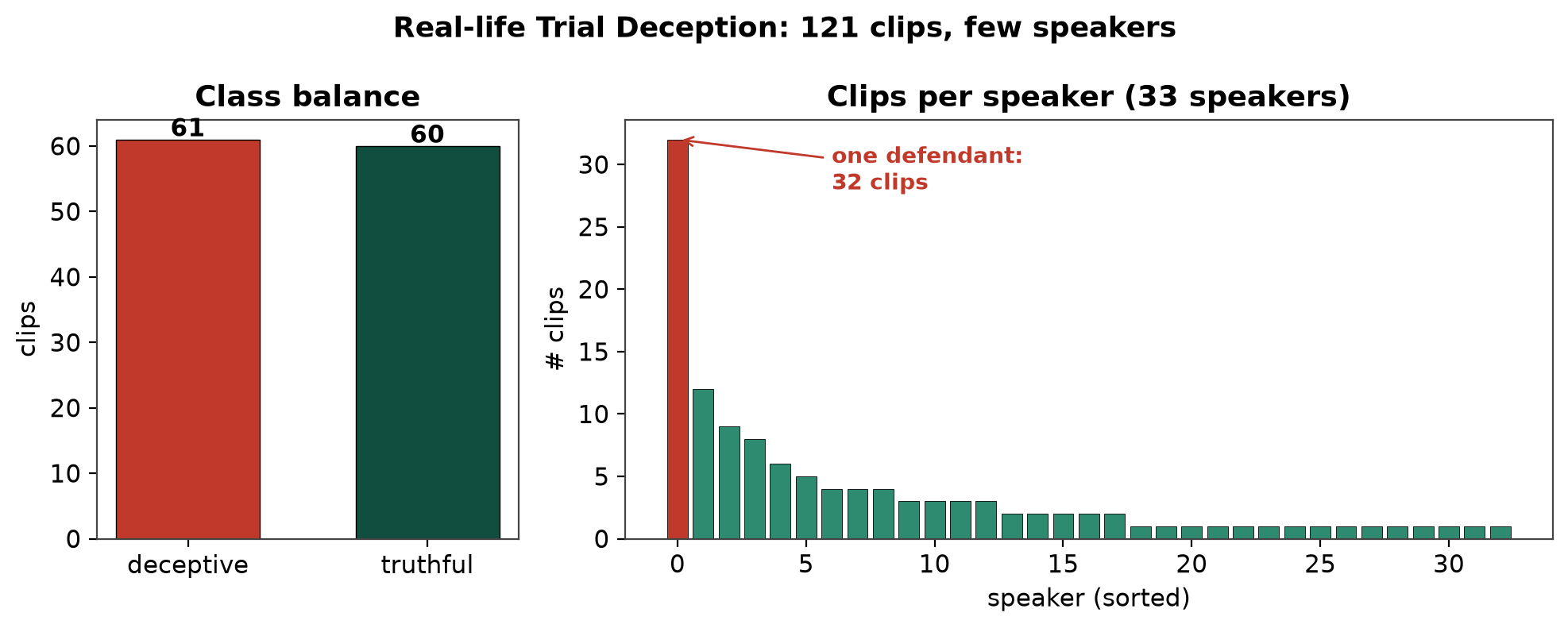
The Real-life Trial Deception dataset has 121 clips (61 deceptive, 60 truthful), averaging ~28 s, taken from public trials and labelled by verdict, acquittal, or exoneration.
The speaker-leakage trap. But it has only 33 speakers: one defendant supplies 32 clips, and 7 appear in both classes. Under the original leave-one-video-out split, holding out one such clip still leaves 31 of the same person in training — so a model learns who is speaking, not whether they lie. We instead use leave-one-speaker-out (LOSO), holding out all of a person's clips together. It scores lower, but it is the only protocol that measures generalisation to a new individual.
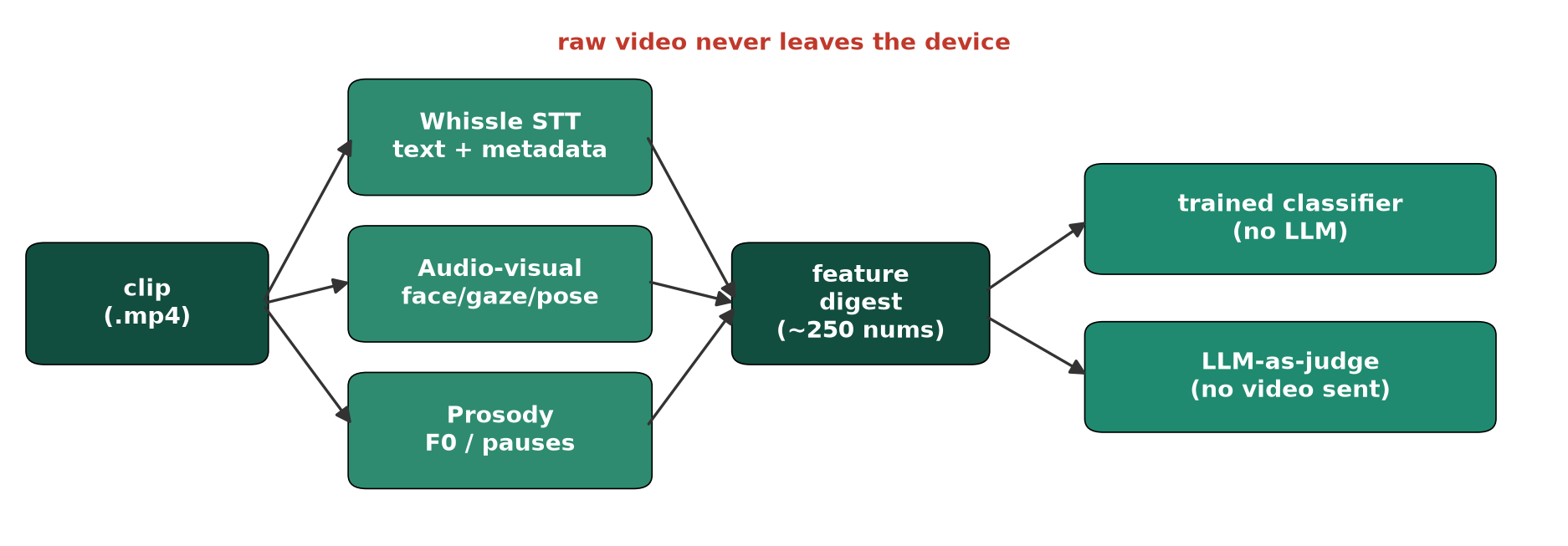
Method
Three on-device lanes convert each clip into a feature digest. No raw media leaves the device.
Text lane (Whissle STT). The transcript, with probability distributions over emotion, age, gender, and 33 intents. A focused deception-intent filter scores labels such as denial, confession, justification, avoidance, and contradiction. A speech-analysis block covers fluency, grammar, vocabulary range, pitch, and rhythm (pause rate, speaking ratio, inter-word intervals). Psycholinguistic rates cover pronouns, negations, and hedges.
Visual lane (audio-visual). Per-frame facial emotion, gaze direction, head pose, blink, and hand gestures, aggregated into behavioural statistics: gaze aversion, head-motion / fidgeting, emotional variability, and blink rate.
Acoustic lane (prosody). Pitch (F0), jitter/shimmer, and pause statistics.
This yields ~250 interpretable features per clip. We study four configurations along two axes (Table 1):
| No LLM | With LLM | |
|---|---|---|
| Zero-shot | majority baseline | LLM-as-judge over our digest (text-only); LLM over raw video |
| Trained | gradient-boosting on the digest | trained late-fusion of digest model + LLM |
Experiments
Setup. All numbers are leave-one-speaker-out, pooled out-of-fold over 121 clips. The trained model is gradient-boosted trees. The LLM judges are zero-shot, prompted neutrally with a base-rate anchor that weights verbal content over weak behavioural cues.
Main results. Table 2 reports every system.
| System | Trained? | LLM? | Video sent? | Accuracy | ROC-AUC |
|---|---|---|---|---|---|
| Majority baseline | — | — | No | 0.504 | 0.500 |
| Self-hosted features → gradient-boosting | Yes | No | No | 0.678 | 0.741 |
| LLM judges our features — Claude Opus 4.8 | No | Yes | No | 0.620 | 0.755 |
| LLM judges our features — Gemini 2.5 Pro | No | Yes | No | 0.669 | 0.704 |
| LLM watches raw video — Gemini 2.5 Pro | No | Yes | Yes | 0.669 | 0.749 |
| Self-hosted + LLM (trained late fusion) | Yes | Yes | Yes | 0.678 | 0.752 |
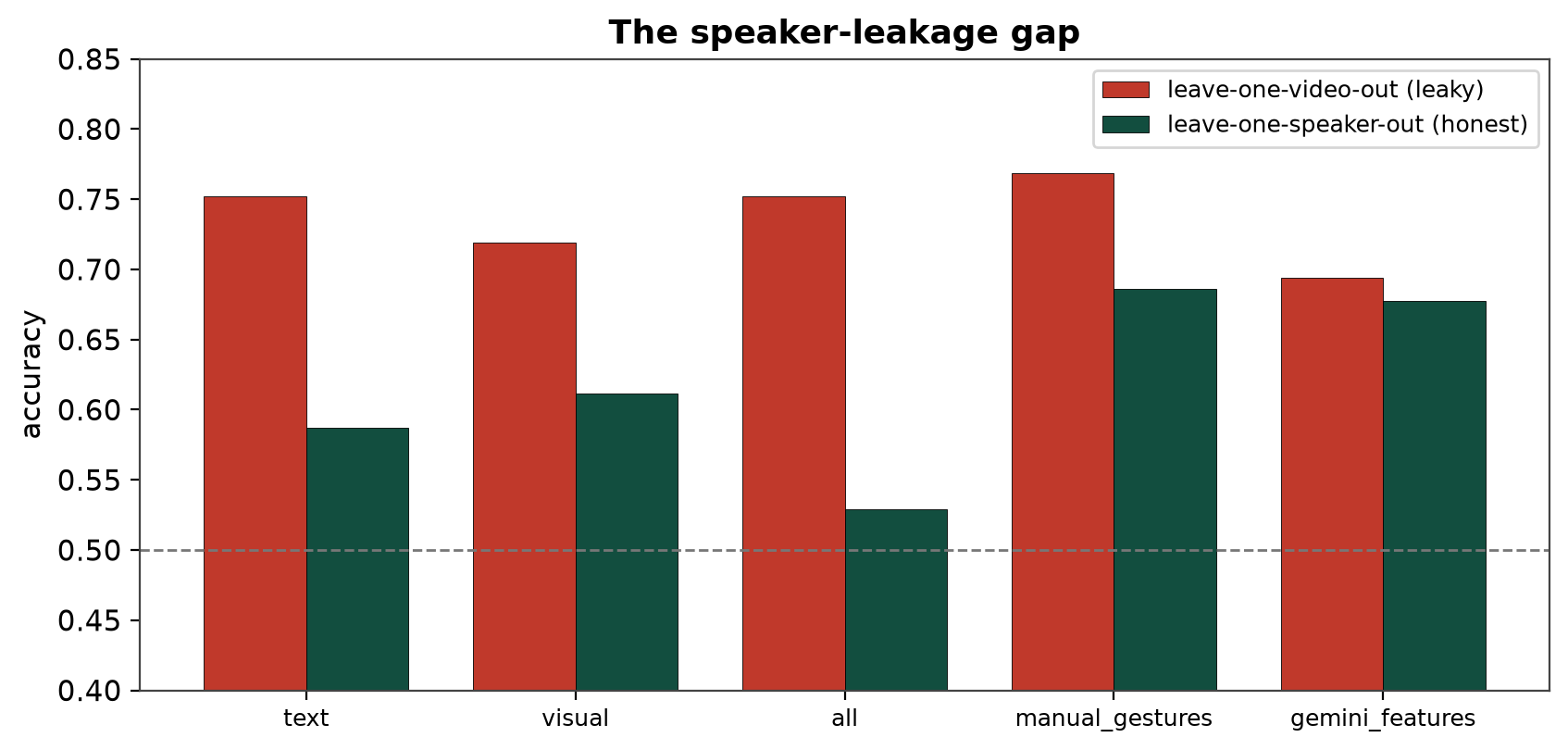
Two independent roads reach ~0.75 without exposing video. Train a small model on the digest (0.741), or hand the digest to a frontier LLM (0.704–0.755). The best single result — Claude Opus 4.8 over our digest, 0.755 — exceeds the same model class watching raw video (0.749).
Comparison to the literature. Under the paper's own leave-one-video-out protocol, our features reproduce and exceed its numbers (0.752–0.777 vs. 0.752; Table 3). Under honest LOSO, everything drops by the size of the leakage.
| Protocol | Original paper | Our features |
|---|---|---|
| Leave-one-video-out (speaker-leaky) | 0.752 | 0.752–0.777 |
| Leave-one-speaker-out (honest) | not reported | 0.741 |
Ablation Studies
Feature groups. We partition the digest into seven groups and measure each alone, plus the AUC lost when it is removed (Table 4; LOSO, full set = 0.741):
| Group | # feats | Alone AUC | Marginal Δ (drop) |
|---|---|---|---|
| STT metadata probs (emotion/age/gender/intent) | 119 | 0.700 | +0.039 |
| Visual (face/gaze/pose/gesture) | 42 | 0.579 | +0.133 |
| Speech-analysis (fluency/grammar/rhythm) | 15 | 0.551 | +0.028 |
| Prosody (librosa) | 21 | 0.448 | +0.028 |
| Lexical (psycholinguistic) | 22 | 0.564 | +0.022 |
| Deception-intent filter | 15 | 0.518 | +0.023 |
| Speech structure (rate/pauses/conf) | 20 | 0.490 | −0.008 |
The STT-metadata group is strongest alone, but the visual lane is the most complementary. Removing it costs 0.133 AUC despite its modest solo score, because it adds signal no other lane captures.
The visual fix. Courtroom faces are small and oblique, and MediaPipe's default confidence rejected ~half the frames. Lowering it raised face-detection from 0.50 to 0.80 and the visual lane from 0.61 to 0.67 AUC. This lifted the self-hosted system from 0.670 to 0.741.
Demographic confound. A few female defendants dominate the deceptive class, so the model's gender and age reads correlate with the label. Dropping all gender/age features lowers the self-hosted AUC to 0.678, our bulletproof number. The with-LLM and direct-video results are unaffected by removing our demographic features.
Prompt sensitivity of the LLM judge. A naive "forensic" prompt makes Gemini over-call deception (AUC 0.62, 79% deceptive calls). Emphasising verbal content over weak behavioural cues, and anchoring the 50/50 base rate, recalibrates it to 0.704 at a 54% deceptive rate. The two LLMs carry opposite priors. Gemini leans deceptive, Claude leans truthful. Claude's strong ranking (0.755) is therefore masked by a conservative threshold (raw accuracy 0.62, ~0.70 thresholded).
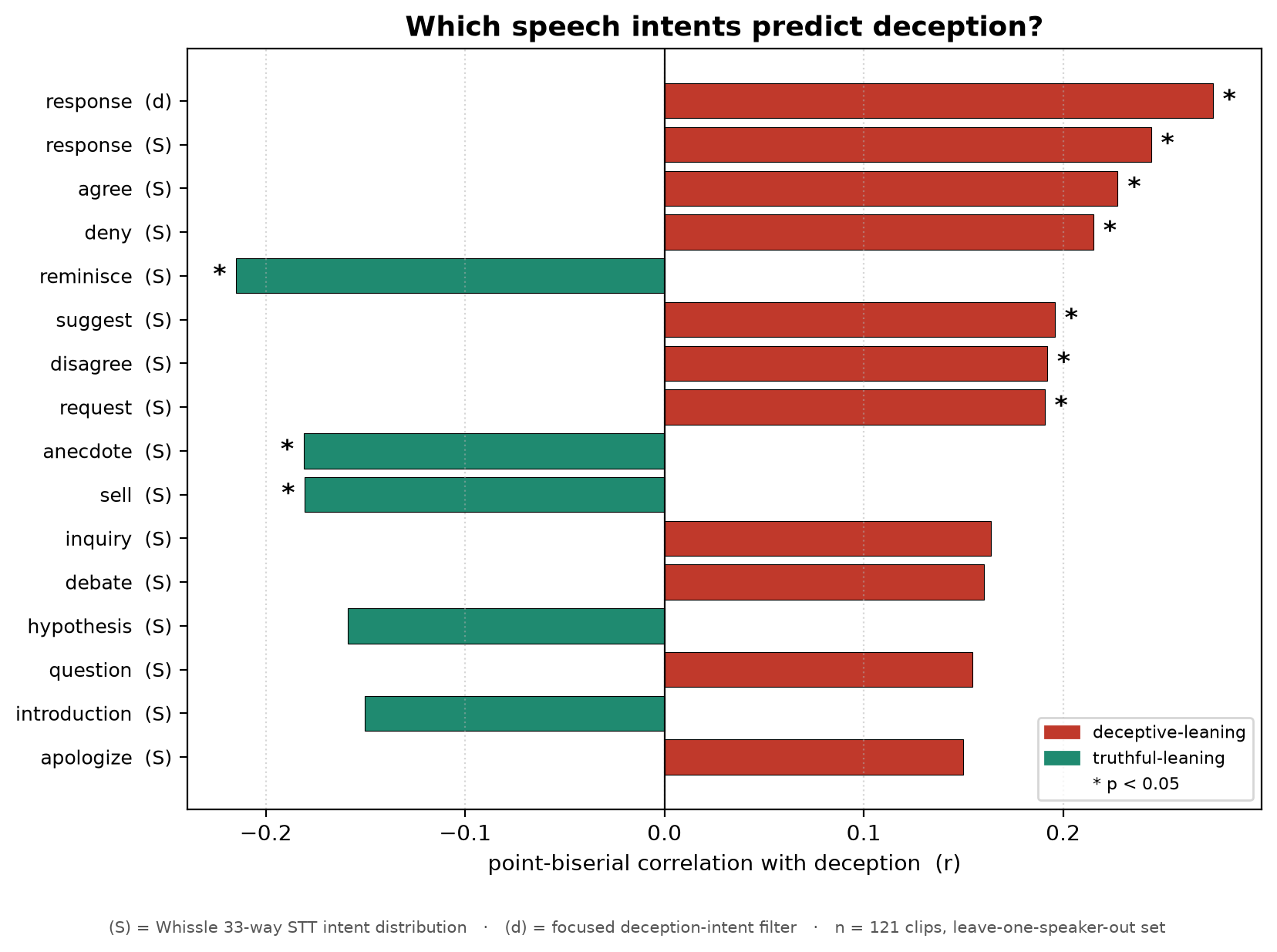
Which intents predict deception? Whissle's STT emits a probability over 33 speech intents per clip, which we probe alongside the deception-intent filter. We correlate each intent's probability with the label (point-biserial r, n = 121), and a clear pattern emerges (Figure 5). Clips lean deceptive when their intent is response, deny, disagree, agree, request, or suggest — the reactive, denial-oriented register of someone fielding accusatory questions. They lean truthful when the intent is reminisce or anecdote, the genuine narrative recall of someone recounting events. We are deliberately cautious. Effect sizes are small (|r| ≤ 0.28). Although 10 of 113 intents reach uncorrected p < 0.05 (vs. ~6 expected by chance), none survive multiple-comparison correction. No single intent is a standalone lie detector. What is meaningful is, first, the coherent, theory-aligned direction — random noise would not place denial and deflection on the deceptive side and genuine recollection on the truthful side — and second, that intents are the single strongest feature family in the ablation (Table 4). The signal lives in the distribution of speech acts, not in any one; confirming individual intents needs a larger corpus.
Cost Analysis
Because we never send the video, the LLM processes far fewer tokens. We measure this with the provider's count_tokens API over a sample of clips (Table 5):
| Input to the LLM | Mean input tokens | Relative |
|---|---|---|
| Raw video (≈296 tokens/s) | 9,810 | 1.0× |
| Our feature digest | 1,261 | 0.13× (7.8× fewer) |
At Gemini 2.5 Pro list pricing, this is ~$1.58 vs. ~$12.26 per 1,000 clips, an ~87% input-cost reduction. It also lowers latency, with no video decode or transfer, and, as shown, raises accuracy. Longer clips save more — up to 10.7× on a 55 s clip.
Limitations and Ethics
This is a research probe on a tiny, US-trial-specific dataset, not a courtroom tool. No model here infers guilt; each predicts a dataset label derived from verdicts. Honest speaker-independent accuracy is ~65–70% — far above chance, but far from proof. Part of the signal is a demographic confound that must be controlled. Deception detection must never be deployed to judge real people without rigorous, contestable, bias-audited validation. The interpretability of a feature-based system, where every cue is named, is a safeguard the opaque LLM verdict lacks.
Conclusion
You need not ship a person's video to a frontier model to detect deception. A compact, interpretable, on-device digest — never exposing raw media — matches a video-watching LLM with a small trained classifier (0.741). It exceeds that model when the digest is handed to a frontier LLM judge (Claude Opus 4.8, 0.755), at 7.8× lower token cost. Privacy, cost, and accuracy point the same way: keep the video on the device.
References
- Pérez-Rosas, Verónica, Mohamed Abouelenien, Rada Mihalcea, and Mihai Burzo. "Deception Detection Using Real-Life Trial Data." Proceedings of the 2015 ACM on International Conference on Multimodal Interaction (ICMI), ACM, 2015.
- Newman, Matthew L., et al. "Lying Words: Predicting Deception from Linguistic Styles." Personality and Social Psychology Bulletin, vol. 29, no. 5, 2003.
- Ekman, Paul. Telling Lies: Clues to Deceit in the Marketplace, Politics, and Marriage. W. W. Norton, 2001.
- Gupta, Viresh, et al. "Bag-of-Lies: A Multimodal Dataset for Deception Detection." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), IEEE, 2019.
- Guo, Xiaobao, et al. "Audio-Visual Deception Detection: DOLOS Dataset and Parameter-Efficient Crossmodal Learning." Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), IEEE, 2023.
- Gemini Team, Google DeepMind. "Gemini 1.5: Unlocking Multimodal Understanding across Millions of Tokens of Context." arXiv, arXiv:2403.05530, 2024.