Beyond Transcription: How a Meta-Aware ASR Model Delivers Words, Emotion, and Intent in 200ms
By Whissle Research Team
Apr 16 2026
47
892

Most speech recognition systems give you words. Just words — a flat stream of text with timestamps. If you want to know how something was said — the speaker's emotion, their intent, how fast they're talking, whether they're using filler words — you need a separate pipeline: send the transcript to an LLM, call a sentiment API, run a classifier. Each step adds latency, cost, and complexity.
Whissle takes a fundamentally different approach. Our Meta-aware Voice Action Model (META-1) is trained on a vocabulary that includes both regular text tokens and metadata action tokens — EMOTION_HAPPY, INTENT_QUESTION, AGE_30_45, GER_FEMALE, SPEAKER_CHANGE. The CTC decoder outputs these inline with the transcript in a single forward pass. One model, one stream, one latency budget — transcription and understanding together at ~200ms.
But CTC-based models have a well-known weakness: they decode each audio frame independently, with zero knowledge of language. The result is mangled word boundaries, phonetic guesses where real words should be, and transcripts that look like someone typed with their elbows. This problem is compounded when the model's vocabulary includes ~10,000 metadata tokens alongside ~8,000 text tokens — the decoder must navigate a much larger output space.
The fix is a traditional n-gram language model — not a neural network. N-gram models (built with KenLM) are essentially lookup tables of word sequence probabilities. They run in sub-millisecond time, need no GPU, operate at CTC frame rate, and carry zero hallucination risk. Instead of picking the single most likely token at each frame (greedy decoding), beam search explores multiple hypotheses and scores them against the n-gram model to find which word sequences actually occur in a language.

We benchmarked this system across four languages — English, Spanish, German, and Hindi — with 1,300 real-world audio samples and five provider configurations. The language model reduced word error rates by up to 3.6% absolute (10.8% relative) on German and Spanish, while the model simultaneously streamed emotion, intent, and demographics at ~200ms — 9x faster than the next closest metadata solution.
This post covers three questions:
- How does a meta-aware ASR model compare against commercial providers — Deepgram Nova-3, AssemblyAI, and Gemini 2.0 Flash — across four languages?
- Does adding a KenLM n-gram language model to the CTC decoder measurably improve accuracy without sacrificing the model's metadata capabilities?
- What's the real cost of getting metadata from each provider — in latency, accuracy, and architectural complexity?
What Changed Since Our Last Benchmark
Our previous benchmark tested English-only with Whissle on CPU. This update introduces five major changes:
- Meta-aware model framing. This benchmark evaluates Whissle's META-1 architecture — a single CTC model that emits transcription tokens and metadata action tokens (emotion, intent, age, gender, speaker change) in one forward pass. Previous benchmarks focused only on transcription accuracy.
- GPU acceleration. Whissle now runs on NVIDIA L4 GPUs via Cloud Run (us-east4), replacing the CPU-only ONNX runtime. Real-time throughput improved significantly.
- N-gram language model integration. KenLM-based 3-gram models, trained on AM training data transcriptions, are fused into CTC beam search decoding. Critically, the LM operates only on text tokens — metadata action tokens are suppressed after log-softmax normalization to preserve proper probability distributions.
- Multilingual benchmarking. English, Spanish, German, and Hindi — with language-matched LM models. Deepgram upgraded from Nova-2 to Nova-3 (their latest multilingual model).
- Metadata extraction benchmarking. We compared the latency and capability of getting metadata (emotion, intent, sentiment, entities) from three approaches: Whissle's single-stream real-time metadata (~200ms), Gemini 2.0 Flash via LLM prompting (1.8–2.2s batch), and Deepgram's batch Audio Intelligence API (0.9–1.2s batch).
The result is a five-provider comparison: Whissle greedy (pure acoustic model with streaming metadata), Whissle + LM (beam search with KenLM), Deepgram Nova-3, AssemblyAI Universal Streaming, and Gemini 2.0 Flash (batch LLM transcription) — tested across four languages with 1,300 total samples.
How We Tested
All providers were tested using real-time WebSocket streaming -- the exact protocol you'd use in production. Audio was streamed in 100ms chunks at 1x real-time speed, simulating a live microphone.
| Provider | Model / Config | Streaming Endpoint |
|---|---|---|
| Whissle (greedy) | GPU + CTC greedy decode | wss://api.whissle.ai/asr/stream |
| Whissle + LM | GPU + CTC beam search + KenLM | wss://api.whissle.ai/asr/stream |
| Deepgram | Nova-3 (multilingual) | wss://api.deepgram.com/v1/listen |
| AssemblyAI | Universal Streaming | wss://streaming.assemblyai.com/v3/ws |
| Gemini 2.0 Flash | LLM batch transcription | generativelanguage.googleapis.com (REST) |
Fair comparison measures:
- All providers received identical audio (PCM int16, mono, 16kHz)
- Both Whissle configurations (greedy and +LM) ran sequentially on each sample, then Deepgram, AssemblyAI, and Gemini ran concurrently
- Text normalized before WER: lowercased, punctuation stripped, whitespace collapsed
- WER computed using the standard jiwer library
- Language parameter set for each provider (e.g.
language=esfor Spanish) - Note on Gemini: Gemini 2.0 Flash is a batch LLM, not a streaming ASR service. Audio is sent as a single request and the full transcript returned at once. Latency numbers reflect total round-trip time, not streaming first-segment latency. This is a fundamentally different architecture -- included to compare accuracy between traditional ASR and LLM-based transcription.
Key metrics:
| Metric | What It Measures |
|---|---|
| WER (mean) | Word Error Rate -- (Insertions + Deletions + Substitutions) / Reference Words, averaged per sample |
| WER (median) | Median per-sample WER -- robust to outliers |
| CER | Character Error Rate -- same formula at character level |
| Time to first segment | Milliseconds from audio stream start to first non-empty transcript |
| RTFX | Real-time factor -- how much faster than real-time the transcription completes |
| Failure rate | Percentage of samples that returned no usable transcript |
The Four Datasets
We chose four speech datasets -- one per language -- from standard academic benchmarks. The European languages use read-speech audiobook narration from LibriSpeech. Hindi uses Meta's conversational speech corpus, testing the system against dialect variation and code-switching.
Dataset 1: LibriSpeech test-clean (English)
The industry baseline. Clean, studio-quality audiobook narration in American English.
| Property | Value |
|---|---|
| Source | openslr/librispeech_asr (HuggingFace) |
| Samples | 100 (from test split) |
| Total audio | 670.6 seconds (~11.2 minutes) |
| Total reference words | 1,870 |
| Language | English (US) |
| KenLM model | ENGLISH.bin (trained on English Wikipedia) |
Dataset 2: Multilingual LibriSpeech -- Spanish
Read speech in Castilian and Latin American Spanish, from the Multilingual LibriSpeech corpus.
| Property | Value |
|---|---|
| Source | WhissleAI/multilingual-libri-test-spanish (HuggingFace) |
| Samples | 100 |
| Total audio | 1,488.4 seconds (~24.8 minutes) |
| Total reference words | 3,250 |
| Language | Spanish |
| KenLM model | EUROPEAN.bin (trained on Spanish, French, German, Portuguese, Italian, and 10 more European language Wikipedias) |
Dataset 3: Multilingual LibriSpeech -- German
Read speech in Standard German, from the same Multilingual LibriSpeech family.
| Property | Value |
|---|---|
| Source | WhissleAI/multilingual-libri-test-german (HuggingFace) |
| Samples | 100 |
| Total audio | 1,451.8 seconds (~24.2 minutes) |
| Total reference words | 2,680 |
| Language | German |
| KenLM model | EUROPEAN.bin (same model as Spanish -- covers all European group languages) |
Dataset 4: Meta STT Hindi (Hindi)
Conversational Hindi with heavy dialect variation (Bihar, UP, etc.), noise markers, and code-switching. A significantly harder benchmark than read speech.
| Property | Value |
|---|---|
| Source | WhissleAI/Meta_STT_HI_Set1 (HuggingFace) |
| Samples | 1,000 (from test split) |
| Total audio | ~7,500 seconds (~125 minutes) |
| Total reference words | 22,055 |
| Language | Hindi (with dialect variation) |
| KenLM model | INDO_ARYAN.bin (trained on Hindi, Marathi, Bengali, Gujarati, and Urdu Wikipedia) |
| Note | AssemblyAI was not tested -- their streaming API does not support Hindi |
The N-Gram Language Model: How It Works
Before diving into results, it's worth understanding how the language model integrates with a CTC decoder that outputs both text and metadata tokens. This is the key engineering challenge: Whissle's META-1 model has ~18,189 tokens in its vocabulary, of which ~9,919 are metadata action tokens (EMOTION_*, INTENT_*, AGE_*, GENDER_*, ENTITY_*, SPEAKER_CHANGE). The language model must enhance transcription accuracy without interfering with metadata prediction.
The Problem: CTC Decoders and the Metadata Vocabulary
A CTC (Connectionist Temporal Classification) model processes audio frame by frame and outputs a probability distribution over the entire token vocabulary at each time step — including both text tokens and metadata action tokens. A greedy decoder picks the most likely token at each frame, collapses consecutive duplicates and blanks, and produces an interleaved stream of text and metadata. It's fast — but it only considers acoustic evidence. It has no knowledge of what words are likely to follow other words.
This means the greedy decoder makes mistakes that a human reader would immediately catch: "he went too the store" instead of "he went to the store." The acoustic signals for "too" and "to" are nearly identical. A language model knows that "to the" is far more probable than "too the" and can correct this.
KenLM: N-Gram Language Models from AM Training Data
The n-gram language models are trained on the text transcriptions from our acoustic model's training data -- the same multilingual speech corpus used to train the Whissle ASR model itself. This is a critical design choice: the LM learns the word distribution and n-gram statistics of the same domain the acoustic model was trained on, ensuring tight alignment between what the model hears and what the LM expects.
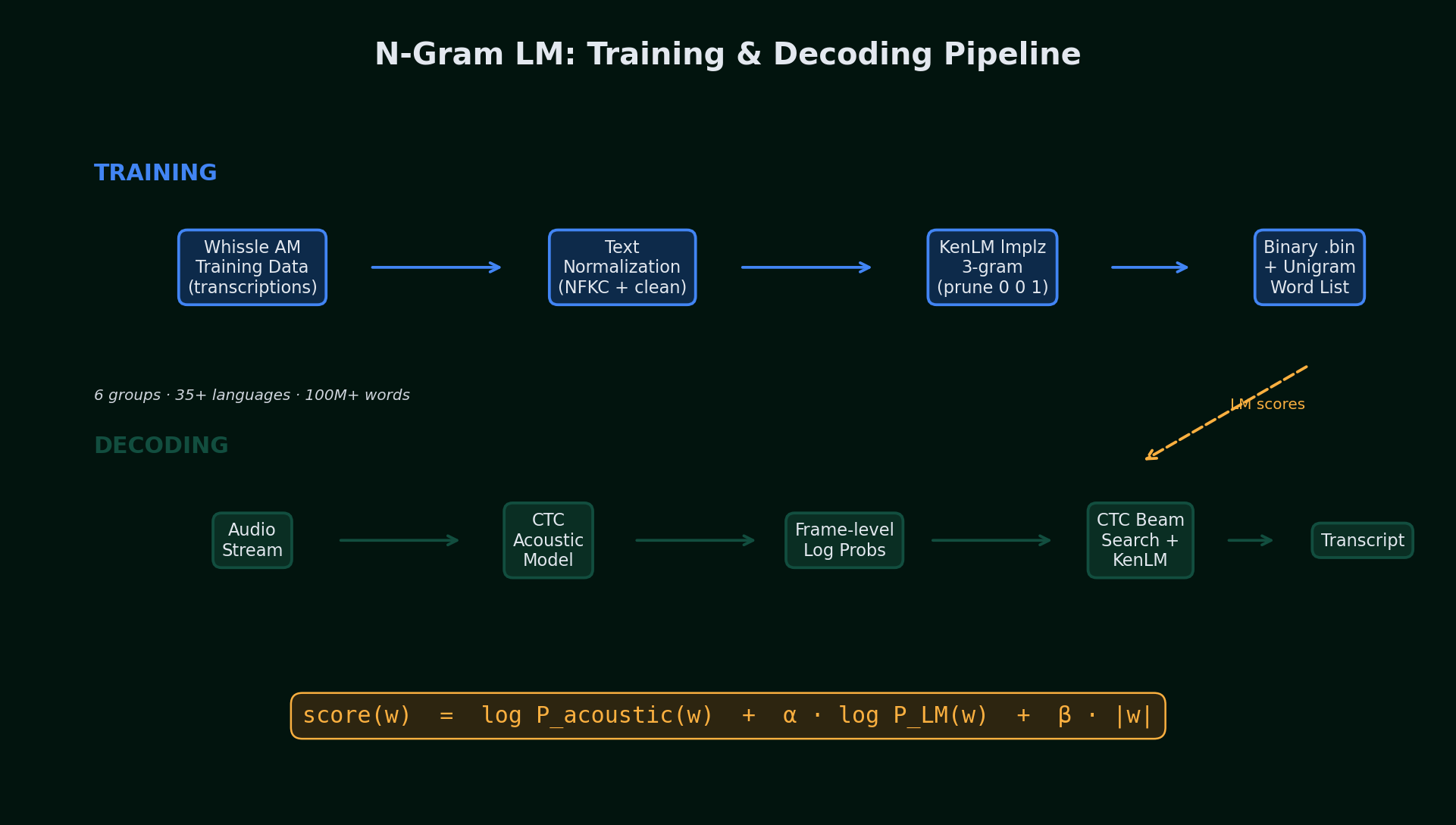
1. Training data extraction. The Whissle acoustic model is trained on a large-scale multilingual speech corpus covering 35+ languages across 6 tokenizer groups. For each group, we extract the reference transcriptions from the training manifests -- the ground-truth text labels paired with the audio. This yields a word-level text corpus of over 100 million words across all groups, with each group's corpus reflecting the actual vocabulary and sentence patterns the ASR model encounters.

2. Text normalization. Transcription text is NFKC-normalized, lowercased, and stripped of non-word characters (preserving Unicode ranges per script -- Latin, Cyrillic, Devanagari, CJK, etc.). Metadata tags (AGE_*, GENDER_*, EMOTION_*, etc.) are removed. This produces a clean word-level corpus per group.
3. N-gram training. We use KenLM's lmplz to train a word-level 3-gram model with pruning thresholds 0 0 1 (keep all unigrams and bigrams, prune trigrams seen fewer than 2 times). The ARPA model is converted to compact binary using build_binary. A unigram word list (top 500K words) is extracted for beam search vocabulary constraint.
4. Per-group deployment. The final artifacts are ENGLISH.bin, EUROPEAN.bin, INDO_ARYAN.bin, etc. -- one per tokenizer group. At server startup, these are loaded into CTCBeamSearchDecoder instances. When a request specifies language=es, the engine resolves Spanish to the EUROPEAN group and uses the corresponding decoder.
CTC Beam Search with Shallow Fusion
The beam search decoder combines two independent scores for each candidate word sequence via shallow fusion:

α (alpha) = 0.1 controls the LM weight. At zero, the decoder ignores the language model entirely (pure acoustic, equivalent to greedy). Higher values let the LM override acoustic evidence. We use a deliberately low value (0.1) so the acoustic model stays dominant -- the LM provides a gentle correction signal, not a sledgehammer. If alpha is set too high, the LM starts hallucinating common words that were never spoken.
β (beta) = 0.5 is the word insertion bonus. Without this, the LM naturally favors shorter sequences (fewer words = fewer chances to get a low-probability transition). Beta adds a small bonus for each word in the candidate, preventing the decoder from producing truncated transcripts. Too high and the decoder inserts phantom words; too low and it drops real ones.
These values were tuned via grid search on 30 samples per language using tune_lm_params.py, sweeping alpha from 0.0 to 1.0 and beta from 0.0 to 2.0. The beam width is 100 candidates, providing a good balance between search thoroughness and latency.
Critical Implementation Details
Several engineering details proved essential for good performance:
- Log-softmax before metadata suppression. Our model vocabulary has ~18,189 tokens, of which ~9,919 are metadata tokens (AGE_*, GENDER_*, EMOTION_*, INTENT_*, ENTITY_*). These must be suppressed for the beam search decoder. We apply log-softmax on the full vocabulary first, then zero out metadata tokens. If metadata is suppressed before normalization, the remaining speech tokens get inflated probabilities (normalization over fewer tokens), making the acoustic model appear ~2x more confident than it really is -- drowning out the LM's corrections.
- Word boundary bias. For BPE tokens where a word-boundary variant (
▁F) and a non-boundary variant (F) both exist, we boost the boundary variant by 5.0 logits. Without this, KenLM tends to merge words (e.g., "SanFrancisco" instead of "San Francisco"). The bias is only applied to tokens with ambiguous counterparts, not unique word-start tokens like▁thousand. - Per-group decoder instances. Each language group gets its own
CTCBeamSearchDecoderloaded at server startup. When a streaming request specifieslanguage=es, the engine resolves Spanish to the EUROPEAN group and uses the corresponding decoder. If no language is specified, the engine auto-detects the language group from the acoustic model's token-range activations.
The result is that adding beam search + LM to a streaming pipeline adds negligible latency (the beam search runs on the same GPU, and the KenLM lookup is a hash table query per frame) while providing meaningful accuracy improvements -- especially for non-English languages.
Results at a Glance
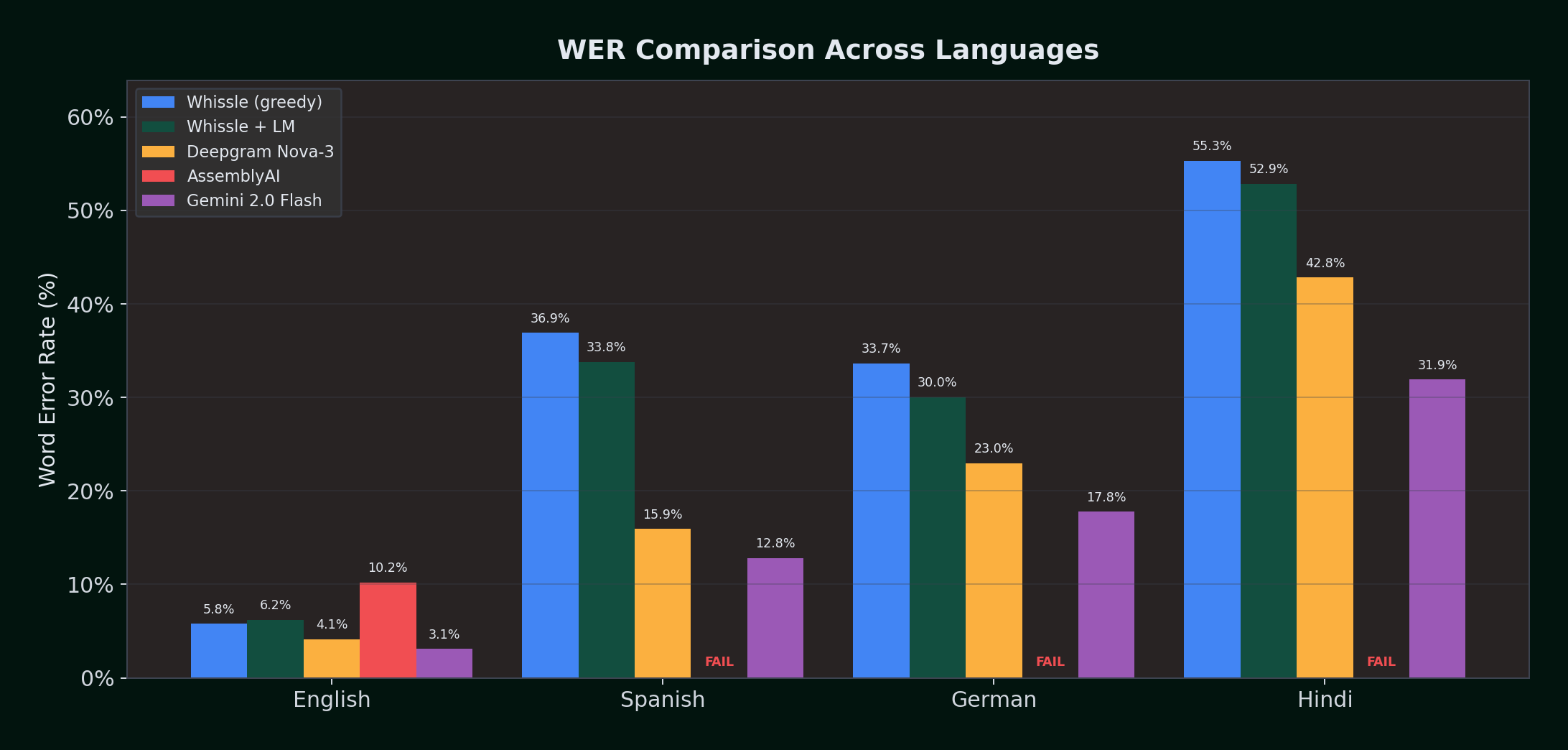
English: LibriSpeech test-clean (100 samples, 670.6s audio)
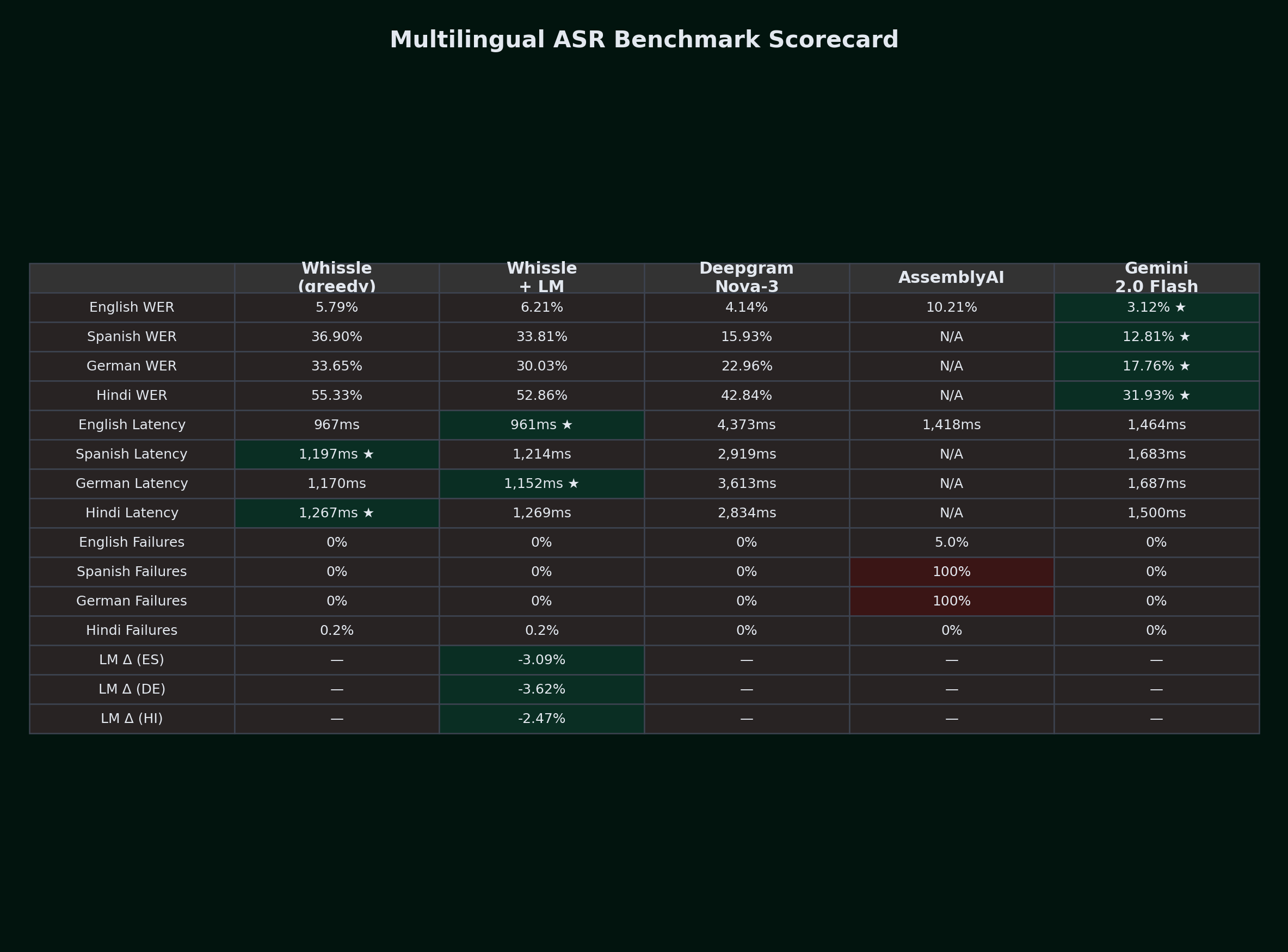
| Metric | Whissle (greedy) | Whissle + LM | Deepgram Nova-3 | AssemblyAI | Gemini 2.0 Flash | Best |
|---|---|---|---|---|---|---|
| WER (mean) | 5.79% | 6.21% | 4.14% | 10.21% | 3.12% | Gemini |
| WER (median) | 3.77% | 0.00% | 0.00% | 7.14% | 0.00% | W+LM/DG/Gem |
| CER (mean) | 2.06% | 2.50% | 1.89% | 10.46% | 1.20% | Gemini |
| First segment (P50) | 967ms | 961ms | 4,373ms | 1,418ms | 1,464ms * | W |
| First segment (P95) | 1,442ms | 1,328ms | 5,509ms | 2,227ms | 2,242ms * | W+LM |
| RTFX (median) | 0.87x | 0.86x | 0.88x | 0.87x | 3.69x | DG |
| Avg confidence | 0.956 | 0.956 | 0.988 | 0.883 | N/A | DG |
| Failed samples | 0 | 0 | 0 | 5 | 0 | -- |
* Gemini latency = total round-trip time (batch LLM, not streaming). Not directly comparable with streaming first-segment latency.
Gemini dominates English accuracy with 3.12% WER -- beating Deepgram Nova-3 (4.14%) by a full percentage point. However, Gemini is a batch LLM: it processes the entire audio file at once and returns a complete transcript, so its 1,464ms latency represents total processing time, not streaming first-segment latency.
LM impact on English: The KenLM model slightly increases mean WER (+0.42%), but improves the median from 3.77% to 0.00% -- more samples get perfect scores. The tradeoff: the ENGLISH.bin model introduces additional insertions (36 vs 22) while reducing substitutions (65 vs 76). For well-trained English acoustic models, the greedy decoder is already strong enough that the LM's corrections are roughly offset by the occasional word it adds.
Whissle delivers the first transcript in under 1 second -- 4.5x faster than Deepgram (967ms vs 4,373ms). Gemini achieves the lowest WER but requires sending the full audio file and waiting for a batch response -- unsuitable for real-time streaming applications.
Spanish: Multilingual LibriSpeech (100 samples, 1,488.4s audio)
| Metric | Whissle (greedy) | Whissle + LM | Deepgram Nova-3 | AssemblyAI | Gemini 2.0 Flash | Best |
|---|---|---|---|---|---|---|
| WER (mean) | 36.90% | 33.81% | 15.93% | 100% FAIL | 12.81% | Gemini |
| WER (median) | 35.48% | 31.82% | 13.71% | -- | 11.45% | Gemini |
| CER (mean) | 11.12% | 10.99% | 5.45% | -- | 2.87% | Gemini |
| First segment (P50) | 1,197ms | 1,214ms | 2,919ms | -- | 1,683ms * | W |
| First segment (P95) | 1,709ms | 1,732ms | 5,282ms | -- | 2,281ms * | W |
| RTFX (median) | 0.94x | 0.94x | 0.95x | -- | 8.67x | Gem |
| Avg confidence | 0.840 | 0.841 | 0.974 | -- | N/A | DG |
| Failed samples | 0 | 0 | 0 | 100 | 0 | -- |
* Gemini latency = total round-trip time (batch LLM, not streaming).
Gemini leads Spanish accuracy with 12.81% WER -- 20% better than Deepgram's 15.93%. As a batch LLM with full audio context, Gemini can leverage its world knowledge for Spanish word sequences in ways that streaming ASR cannot.
LM impact on Spanish: -3.09% absolute WER reduction (36.90% → 33.81%, or 8.4% relative improvement). The EUROPEAN.bin KenLM model -- trained on Spanish, French, German, Portuguese, Italian, and 10 other European language Wikipedias -- provides strong linguistic priors for Spanish word sequences.
The error breakdown tells the story: deletions dropped from 182 to 145 (the LM fills in words the acoustic model missed), substitutions dropped from 919 to 835 (the LM corrects acoustically ambiguous words), and correctly recognized words increased from 2,149 to 2,270 out of 3,250 total.
AssemblyAI's Universal Streaming returned zero transcripts for all 100 Spanish samples -- a 100% failure rate. This makes it unusable for any non-English streaming application.
German: Multilingual LibriSpeech (100 samples, 1,451.8s audio)
| Metric | Whissle (greedy) | Whissle + LM | Deepgram Nova-3 | AssemblyAI | Gemini 2.0 Flash | Best |
|---|---|---|---|---|---|---|
| WER (mean) | 33.65% | 30.03% | 22.96% | 100% FAIL | 17.76% | Gemini |
| WER (median) | 32.88% | 30.20% | 21.53% | -- | 16.00% | Gemini |
| CER (mean) | 9.61% | 8.35% | 6.59% | -- | 4.45% | Gemini |
| First segment (P50) | 1,170ms | 1,152ms | 3,613ms | -- | 1,687ms * | W+LM |
| First segment (P95) | 2,231ms | 2,219ms | 5,460ms | -- | 2,126ms * | Gem * |
| RTFX (median) | 0.93x | 0.93x | 0.95x | -- | 8.22x | Gem |
| Avg confidence | 0.877 | 0.876 | 0.940 | -- | N/A | DG |
| Failed samples | 0 | 0 | 0 | 100 | 0 | -- |
* Gemini latency = total round-trip time (batch LLM, not streaming).
Gemini leads German accuracy with 17.76% WER -- 23% better than Deepgram's 22.96%. German compound words like "Lebensversicherungsgesellschaft" benefit from Gemini's full-context LLM decoding, which can resolve compound boundaries that streaming decoders split incorrectly.
LM impact on German: -3.62% absolute WER reduction (33.65% → 30.03%, or 10.8% relative improvement). German shows the strongest LM benefit of all four languages, likely because German's compound words and case morphology create many acoustically ambiguous sequences that the LM can disambiguate.
The most dramatic change is in deletions: they dropped from 93 to 38 -- a 59% reduction. The LM is recovering words that the greedy decoder was losing entirely. Correctly recognized words jumped from 1,856 to 1,989 out of 2,680 reference words.
AssemblyAI again returned zero transcripts for all 100 German samples. Combined with the Spanish result, this confirms that AssemblyAI's streaming API does not support non-English languages.
Hindi: Meta STT (1,000 samples, ~7,500s audio)
| Metric | Whissle (greedy) | Whissle + LM | Deepgram Nova-3 | Gemini 2.0 Flash | Best |
|---|---|---|---|---|---|
| WER (mean) | 55.33% | 52.86% | 42.84% | 31.93% | Gemini |
| WER (median) | 50.00% | 48.28% | 37.50% | 25.00% | Gemini |
| CER (mean) | 37.54% | 38.68% | 35.68% | 21.92% | Gemini |
| First segment (P50) | 1,267ms | 1,269ms | 2,834ms | 1,500ms * | W |
| First segment (P95) | 2,095ms | 2,234ms | 5,411ms | 2,078ms * | W |
| RTFX (median) | 0.83x | 0.82x | 0.93x | TBD | DG |
| Avg confidence | 0.685 | 0.693 | 0.928 | N/A | DG |
| Failed samples | 2 (0.2%) | 2 (0.2%) | 0 (0%) | 0 (0%) | DG/Gem |
* Gemini latency = total round-trip time (batch LLM, not streaming).
Gemini dominates Hindi accuracy with 31.93% WER -- a massive 10.91% absolute improvement over Deepgram (42.84%) and 20.93% over Whissle+LM (52.86%). Hindi is where Gemini's LLM capabilities shine brightest: its world knowledge handles code-switching, dialect variation, and Hindi morphology far better than specialized streaming ASR.
LM impact on Hindi: -2.47% absolute WER reduction (55.33% → 52.86%, or 4.5% relative improvement). The INDO_ARYAN.bin KenLM model -- trained on Hindi, Marathi, Bengali, Gujarati, and Urdu Wikipedia -- helps the most on longer utterances, where the LM has more context to correct word sequences.
The substitution reduction is the primary lever: 7,048 → 6,089 (-959 fewer substitutions), with correctly recognized words increasing from 11,723 to 12,584 (+861). Insertions do increase (456 → 605), a consistent pattern across all languages.
The high absolute WER is expected for this dataset -- Meta STT contains conversational Hindi with heavy dialect variation (Bihar, Uttar Pradesh), noise markers, and Hindi-English code-switching. Among streaming providers, Deepgram leads by ~10% absolute, but Gemini's batch LLM transcription crushes both streaming providers with 31.93% WER.
Whissle delivers first transcripts 2.2x faster than Deepgram on Hindi (1,267ms vs 2,834ms). Gemini achieves the lowest WER (31.93%) but requires batch processing. AssemblyAI was not tested as their streaming API does not support Hindi.
The Language Model Impact: A Cross-Language View
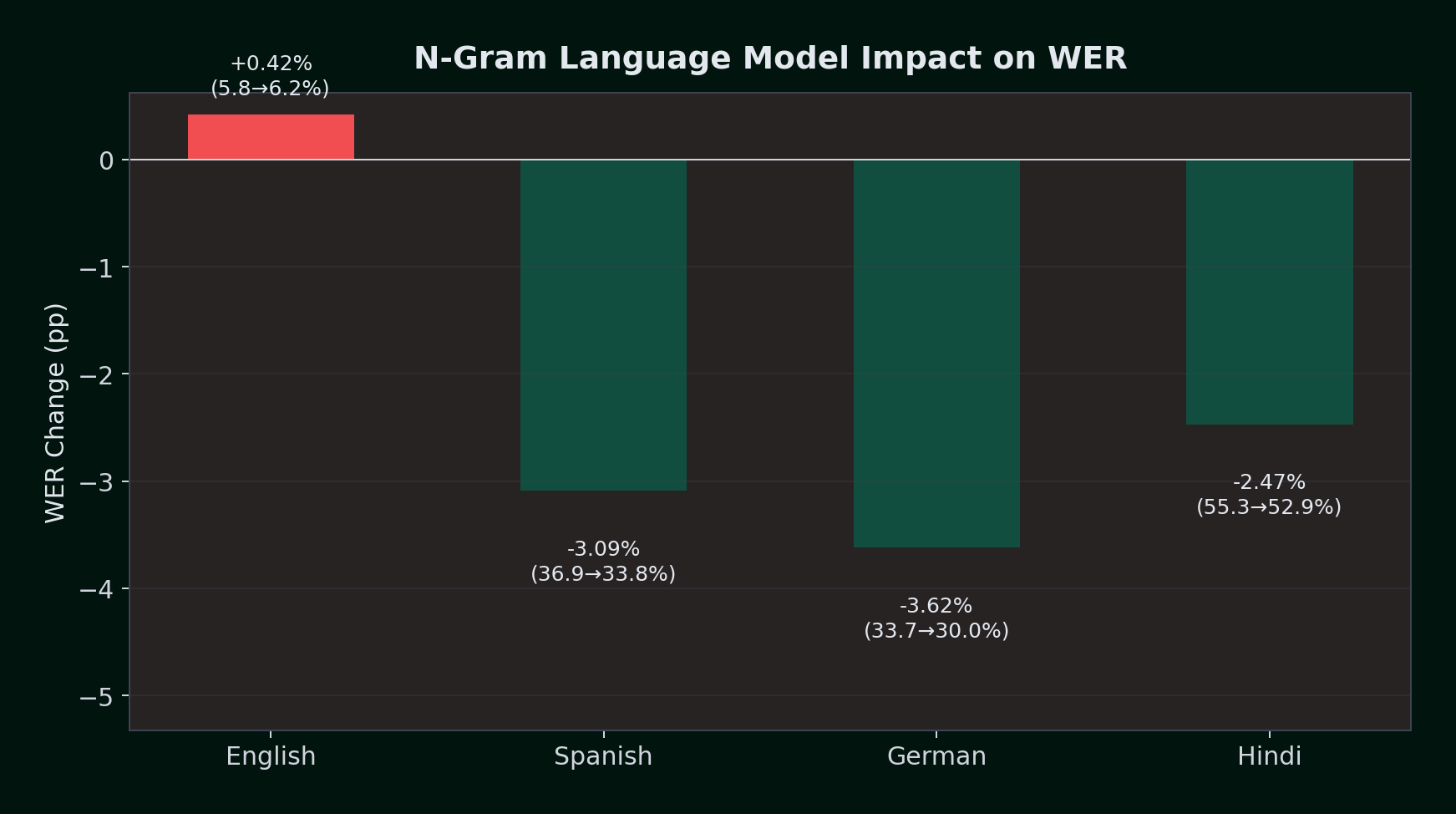
| Language | Greedy WER | +LM WER | Absolute Change | Relative Change | Direction |
|---|---|---|---|---|---|
| English | 5.79% | 6.21% | +0.42% | +7.3% | Slight hurt |
| Spanish | 36.90% | 33.81% | -3.09% | -8.4% | Clear improvement |
| German | 33.65% | 30.03% | -3.62% | -10.8% | Strong improvement |
| Hindi | 55.33% | 52.86% | -2.47% | -4.5% | Clear improvement |
The pattern is clear: the LM helps most where the acoustic model struggles most. On English -- where the greedy decoder already achieves 5.79% WER -- the LM is roughly neutral (slightly worse mean, slightly better median). On Spanish, German, and Hindi -- where greedy WER is 33--55% -- the LM provides 2.5--3.6% absolute improvement.
Why the LM Helps Non-English More Than English
Three factors explain this asymmetry:
- English acoustic training data dominance. The acoustic model was trained on significantly more English data than any other language. This means the English acoustic scores are already well-calibrated -- the greedy decoder makes good choices because the model is confident and usually right. For Spanish and German, the acoustic model is less certain, creating more room for the LM to help.
- Morphological complexity. Spanish verb conjugations, German compound words, and Hindi's agglutinative morphology all create acoustically ambiguous token sequences. The LM's n-gram statistics help the decoder navigate these ambiguities.
- Insertion-deletion tradeoff. For English, the LM introduces extra insertions (+14 words, from 22 to 36) while only modestly reducing substitutions (-11, from 76 to 65). For German, the LM's insertion increase (+43) is more than compensated by a massive deletion decrease (-55, from 93 to 38). For Hindi, substitution reduction is the main lever (-959 substitutions, the largest absolute improvement across all languages).
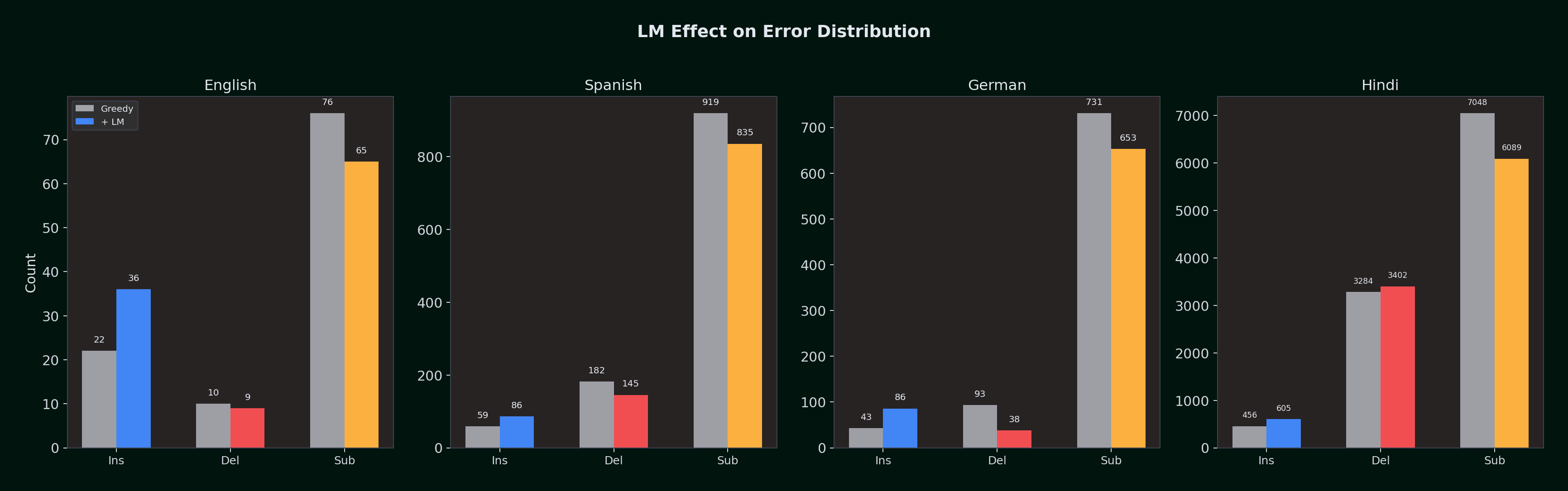
Error Composition with and without LM
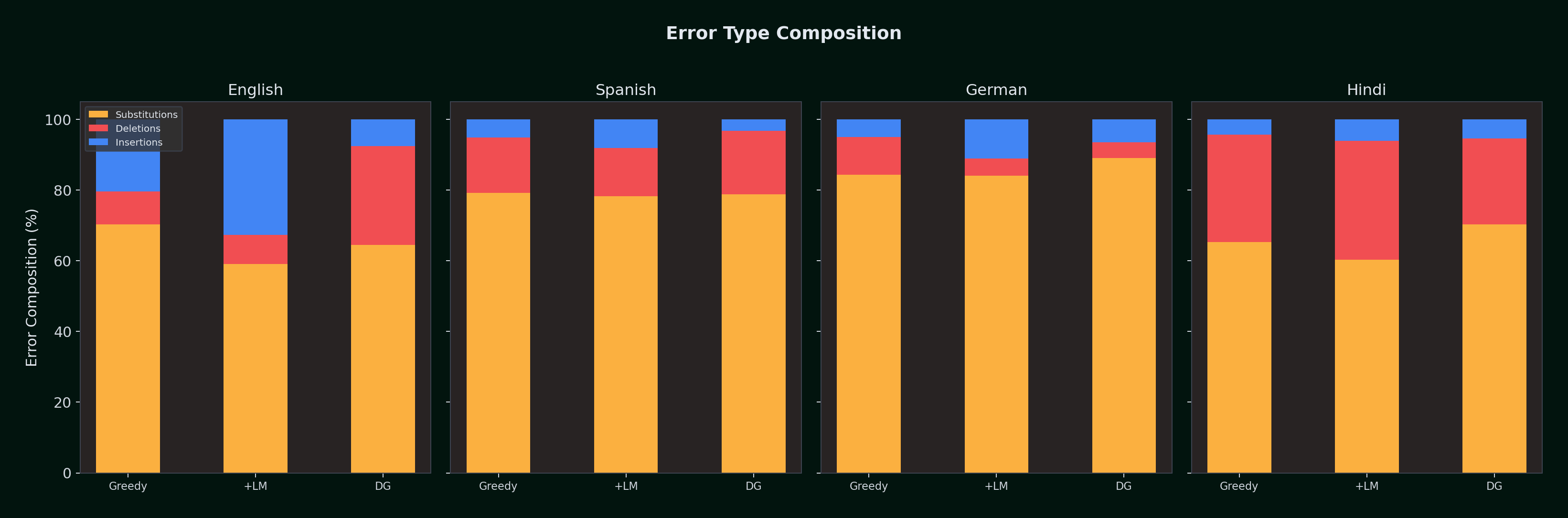
| Language | Config | Insertions | Deletions | Substitutions | Correct | Total Ref |
|---|---|---|---|---|---|---|
| English | Greedy | 22 | 10 | 76 | 1,784 | 1,870 |
| English | +LM | 36 | 9 | 65 | 1,796 | 1,870 |
| Spanish | Greedy | 59 | 182 | 919 | 2,149 | 3,250 |
| Spanish | +LM | 86 | 145 | 835 | 2,270 | 3,250 |
| German | Greedy | 43 | 93 | 731 | 1,856 | 2,680 |
| German | +LM | 86 | 38 | 653 | 1,989 | 2,680 |
| Hindi | Greedy | 456 | 3,284 | 7,048 | 11,723 | 22,055 |
| Hindi | +LM | 605 | 3,402 | 6,089 | 12,584 | 22,055 |
The LM consistently increases insertions across all languages (it's more willing to "guess" a word than stay silent) while decreasing substitutions. For English, these effects roughly cancel out. For Spanish and German, the deletion and substitution reductions decisively outweigh the insertion increase. For Hindi, the LM's primary contribution is substitution reduction (-959), recovering 861 additional correct words from a 22,000-word corpus.
Latency: Whissle Delivers 3--4x Faster First Segments
How quickly does the first transcript appear after audio starts streaming? This matters enormously for live captioning, real-time coaching, and conversational AI.
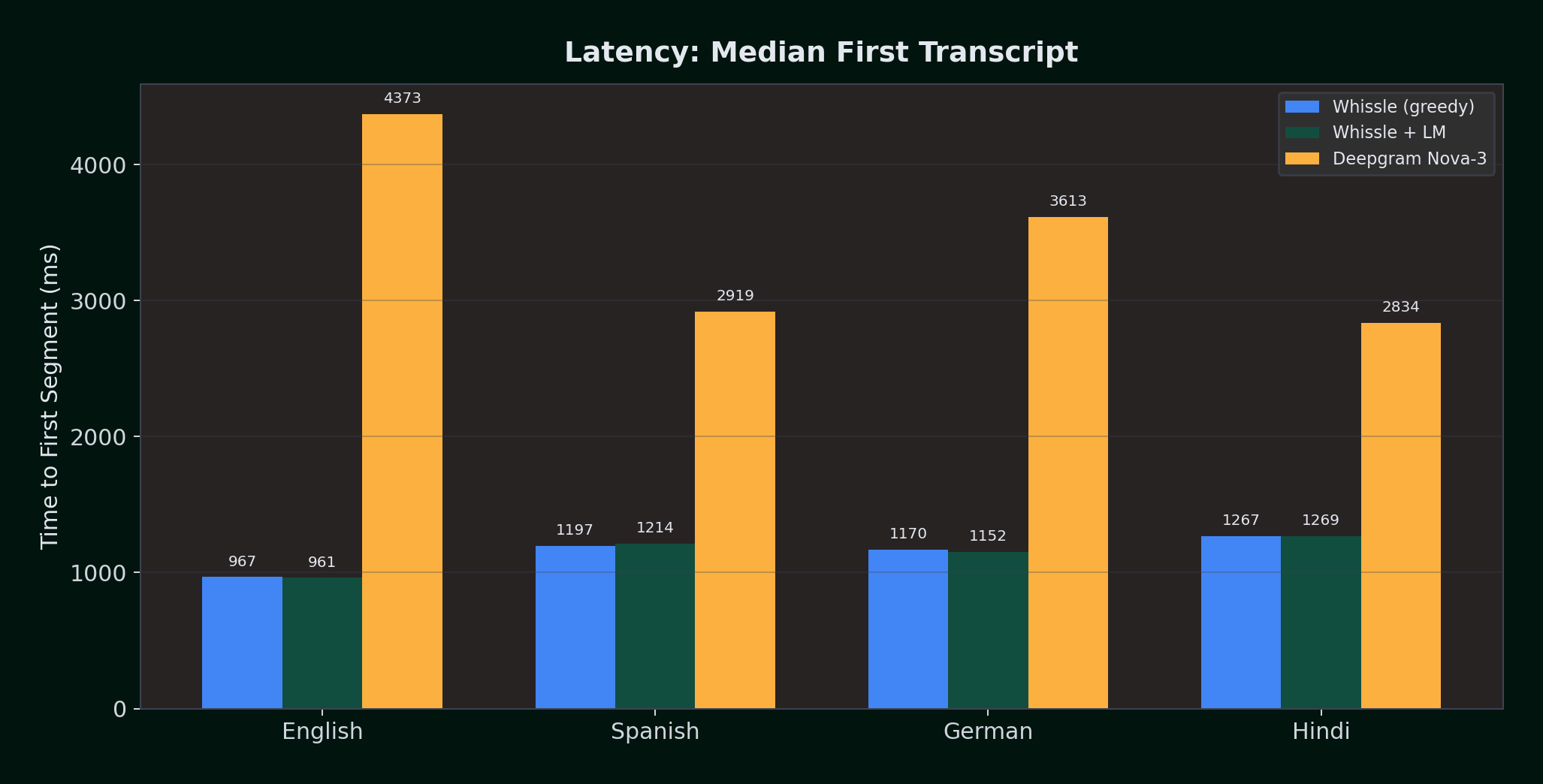
| Language | Whissle (greedy) | Whissle + LM | Deepgram Nova-3 | Whissle Advantage |
|---|---|---|---|---|
| English | 967ms | 961ms | 4,373ms | 4.5x faster |
| Spanish | 1,197ms | 1,214ms | 2,919ms | 2.4x faster |
| German | 1,170ms | 1,152ms | 3,613ms | 3.1x faster |
| Hindi | 1,267ms | 1,269ms | 2,834ms | 2.2x faster |
Whissle delivers the first transcript 2.2--4.5x faster than Deepgram across every language. The LM adds negligible latency (~2ms difference on average) because KenLM lookups are hash table queries that execute in microseconds.
Latency percentiles:
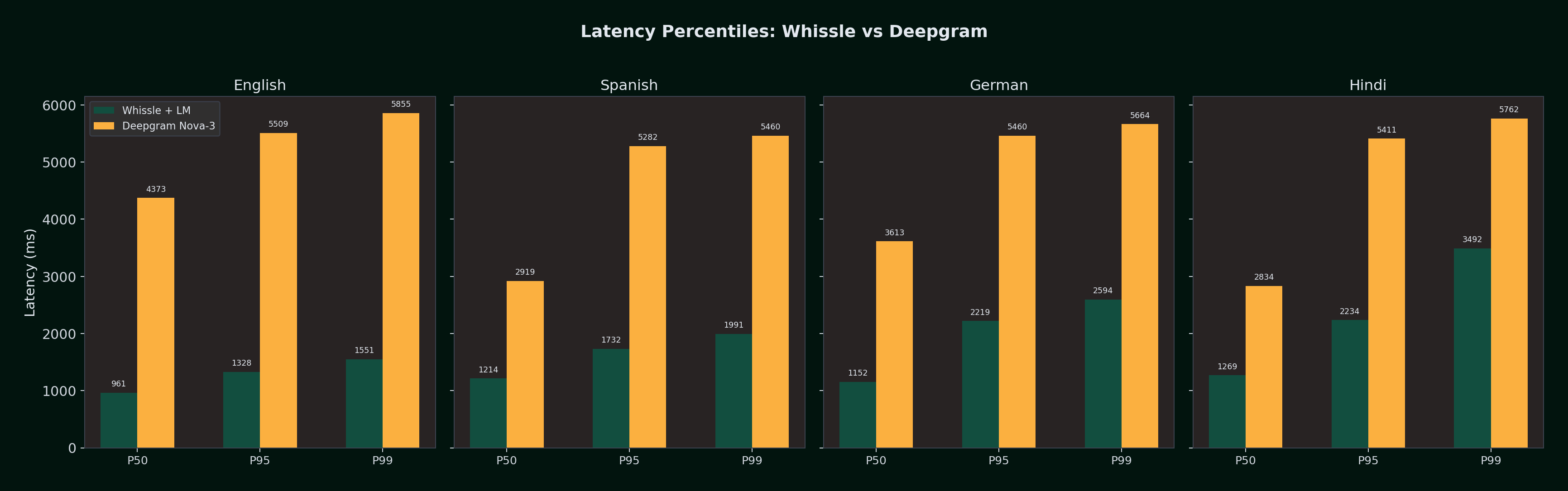
| Percentile | Whissle +LM (EN) | DG Nova-3 (EN) | Whissle +LM (ES) | DG Nova-3 (ES) | Whissle +LM (DE) | DG Nova-3 (DE) | Whissle +LM (HI) | DG Nova-3 (HI) |
|---|---|---|---|---|---|---|---|---|
| P50 | 961ms | 4,373ms | 1,214ms | 2,919ms | 1,152ms | 3,613ms | 1,269ms | 2,834ms |
| P95 | 1,328ms | 5,509ms | 1,732ms | 5,282ms | 2,219ms | 5,460ms | 2,234ms | 5,411ms |
| P99 | 1,551ms | 5,855ms | 1,991ms | 5,460ms | 2,594ms | 5,664ms | 3,492ms | 5,762ms |
Even at P99, Whissle stays under 3.5 seconds across all languages. Deepgram's P95 and P99 consistently land in the 5.3--5.9s range, suggesting a fixed buffering strategy independent of language.
Reliability: AssemblyAI Fails Completely on Non-English
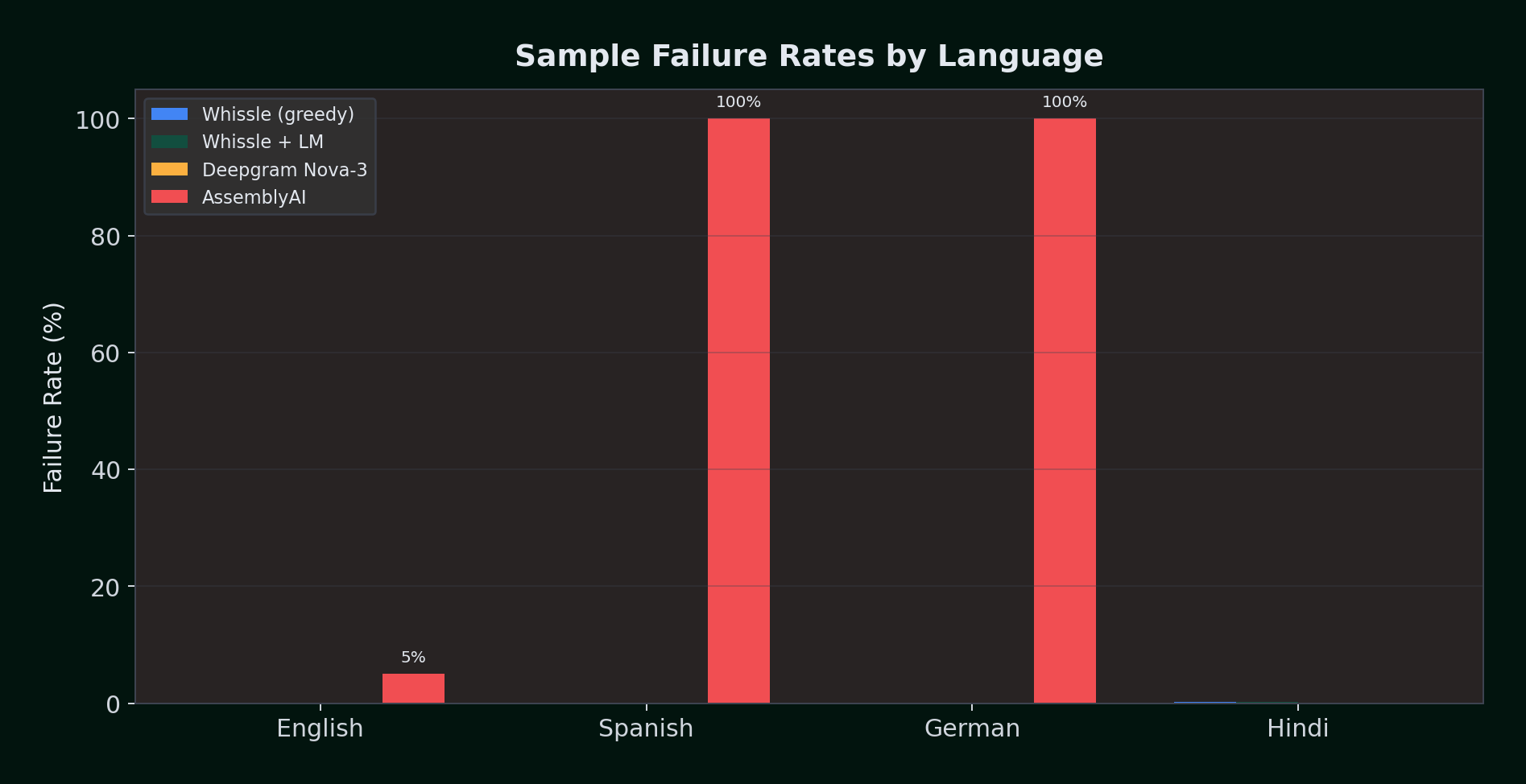
| Language | Samples | Whissle (greedy) | Whissle + LM | Deepgram Nova-3 | AssemblyAI | Gemini 2.0 Flash |
|---|---|---|---|---|---|---|
| English | 100 | 0 (0%) | 0 (0%) | 0 (0%) | 5 (5%) | 0 (0%) |
| Spanish | 100 | 0 (0%) | 0 (0%) | 0 (0%) | 100 (100%) | 0 (0%) |
| German | 100 | 0 (0%) | 0 (0%) | 0 (0%) | 100 (100%) | 0 (0%) |
| Hindi | 1,000 | 2 (0.2%) | 2 (0.2%) | 0 (0%) | N/A | 0 (0%) |
| Total | 1,300 | 2 (0.15%) | 2 (0.15%) | 0 (0%) | 205 / 300 tested (68.3%) | 0 / 1,300 (0%) |
Deepgram and Gemini both achieved zero failures across all tested samples. Whissle had 2 failures on Hindi (0.2%) and zero on all other languages. AssemblyAI was only testable on English (where it failed 5%) -- it returned zero transcripts for all Spanish and German samples. Hindi was not tested with AssemblyAI as their streaming API does not support it.
For any multilingual production application, AssemblyAI's streaming API is not viable. Their batch/pre-recorded API may support additional languages, but the real-time streaming endpoint tested here does not.
Character Error Rate: A Finer-Grained View
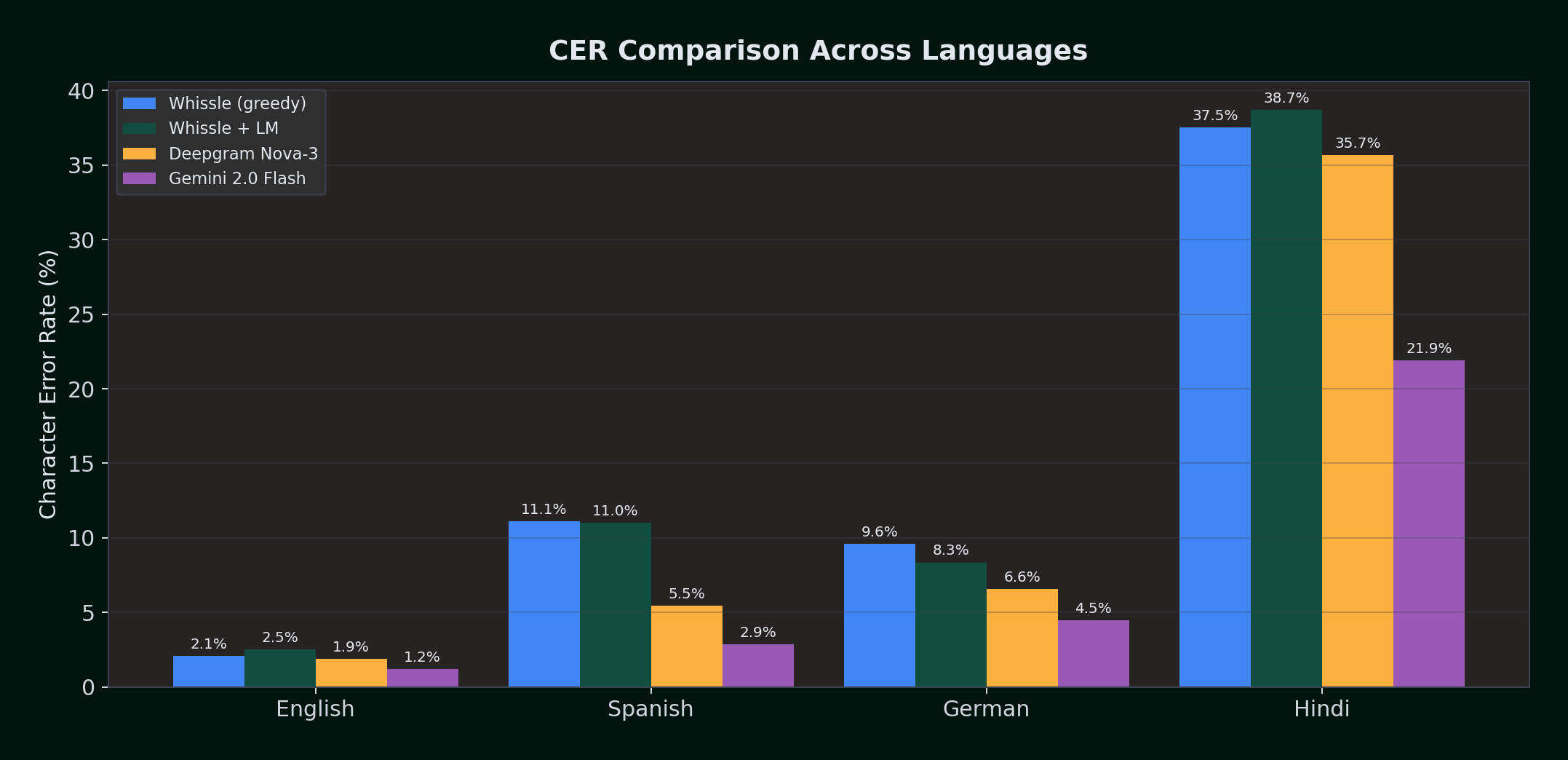
CER measures accuracy at the character level -- useful for morphologically rich languages where a single wrong character can change a word's meaning (e.g., German "Haus" vs "Maus").
| Language | Whissle (greedy) | Whissle + LM | Deepgram Nova-3 | Gemini 2.0 Flash | LM Impact |
|---|---|---|---|---|---|
| English | 2.06% | 2.50% | 1.89% | 1.20% | +0.44% (worse) |
| Spanish | 11.12% | 10.99% | 5.45% | 2.87% | -0.13% (neutral) |
| German | 9.61% | 8.35% | 6.59% | 4.45% | -1.26% (better) |
| Hindi | 37.54% | 38.68% | 35.68% | 21.92% | +1.14% (worse) |
German shows the strongest CER improvement from the LM (-1.26%), consistent with its morphological complexity creating more character-level errors that the LM can correct. Hindi CER slightly increases with the LM (+1.14%), even though WER improves -- the LM corrects more words but sometimes introduces longer substitutions at the character level. Spanish CER is nearly unchanged, suggesting the LM's word-level improvements for Spanish come from recovering whole words (reducing deletions) rather than correcting individual characters.
Correct Word Recovery

Another way to visualize the LM's effect: how many words out of the reference text were correctly recognized?
| Language | Ref Words | Greedy Correct | +LM Correct | DG Nova-3 Correct | Gemini Correct | LM Gain |
|---|---|---|---|---|---|---|
| English | 1,870 | 1,784 (95.4%) | 1,796 (96.0%) | 1,797 (96.1%) | 1,823 (97.5%) | +12 words |
| Spanish | 3,250 | 2,149 (66.1%) | 2,270 (69.8%) | 2,765 (85.1%) | 2,859 (87.9%) | +121 words |
| German | 2,680 | 1,856 (69.3%) | 1,989 (74.2%) | 2,135 (79.7%) | 2,258 (84.3%) | +133 words |
| Hindi | 22,033 | 11,723 (53.2%) | 12,584 (57.1%) | 14,460 (65.5%) | 16,322 (74.1%) | +861 words |
The LM recovers 121 additional correct words in Spanish, 133 in German, and 861 in Hindi -- meaningful improvements in transcript quality. Gemini achieves the highest correct-word rates for English, Spanish, and German -- recovering 97.5%, 87.9%, and 84.3% of reference words respectively. For German, the n-gram LM closes 28% of the gap between greedy Whissle and Deepgram, while Gemini goes even further with 84.3% recovery.
Scorecard
Choose Gemini 2.0 Flash when:
- You need the absolute lowest WER and batch/offline processing is acceptable
- Real-time streaming is not required -- you can send full audio files and wait for complete transcripts
- You want LLM-grade language understanding applied to transcription (e.g., resolving ambiguous words from full-context understanding)
Choose Deepgram when:
- You need the best streaming ASR accuracy -- Deepgram leads all streaming providers across every language
- You can tolerate 3--5 second latency to first transcript
- You need multilingual streaming support with the lowest WER among streaming providers
Choose Whissle when:
- You need more than words — streaming emotion, intent, speech rate, filler detection, and demographics alongside transcription, in the same stream, at the same latency
- You need the fastest first-segment response (~1 second) for real-time coaching, live captions, or voice agents
- You need metadata at ~200ms, not 1–2 seconds via separate batch API calls
- Zero failure rates are non-negotiable
- You want to self-host ASR on your own GPU infrastructure (eliminating per-minute costs)
- You need n-gram LM customization — bring your own domain-specific language model for medical, legal, or financial vocabulary
Avoid AssemblyAI streaming for:
- Any non-English language (100% failure rate on Spanish and German)
- Production applications requiring reliable streaming (5% failure rate even on English)
Streaming vs. Batch: Does Pre-Recorded Mode Help?
Streaming ASR processes audio in real time as it arrives. Batch (pre-recorded) ASR processes the entire audio file at once, giving the engine full context before producing output. Does this make a difference?
We ran identical audio through both streaming and batch APIs for Whissle and Deepgram across all four languages. For Whissle batch, we tested both greedy decoding and KenLM language model rescoring.
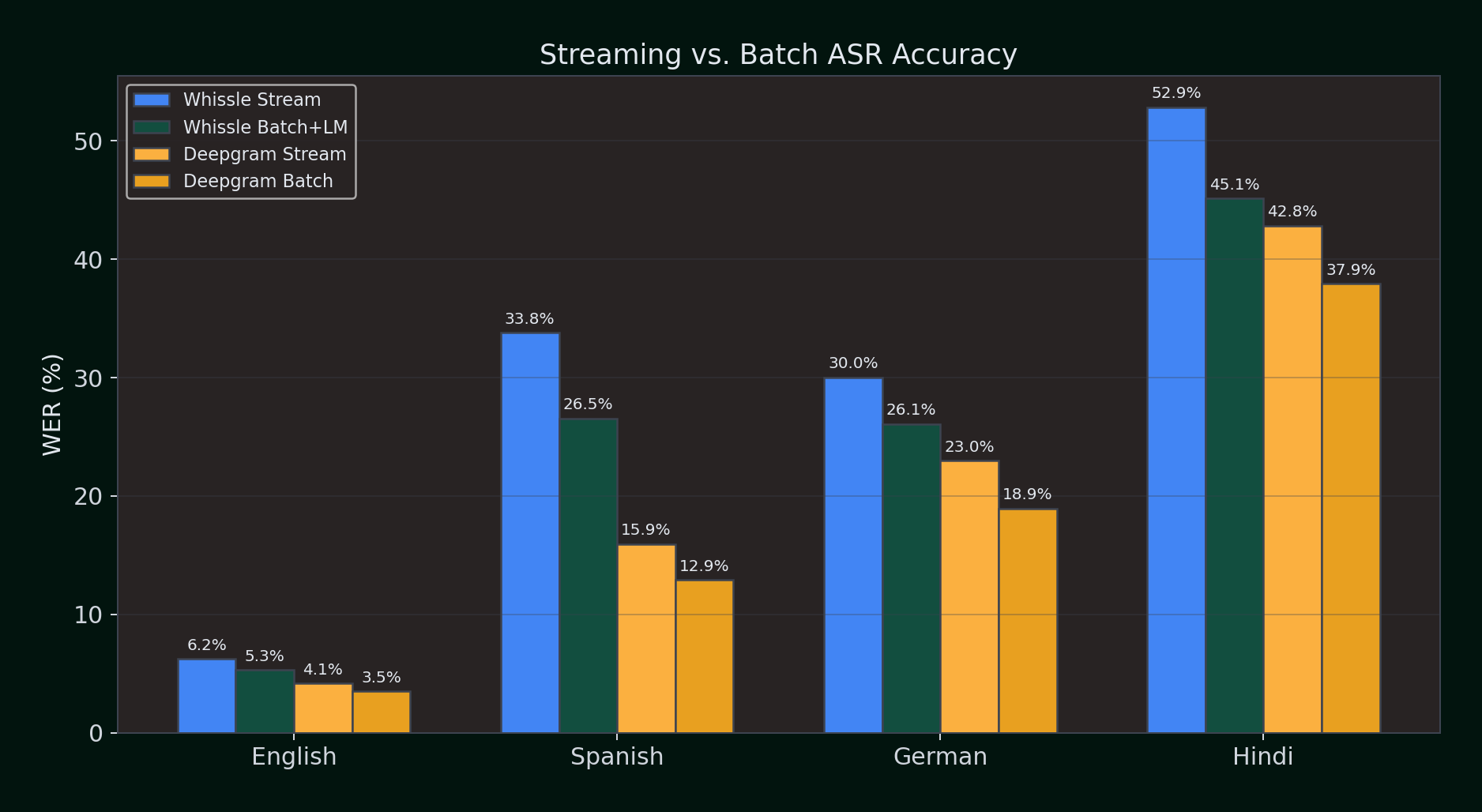
Streaming vs. Batch WER (%) — lower is better:
| Language | Whissle Stream | Whissle Batch+LM | Deepgram Stream | Deepgram Batch |
|---|---|---|---|---|
| English | 6.21% | 5.31% | 4.14% | 3.48% |
| Spanish | 33.81% | 26.54% | 15.93% | 12.92% |
| German | 30.03% | 26.09% | 22.96% | 18.95% |
| Hindi | 52.86% | 45.15% | 42.84% | 37.91% |
Key observations:
- Batch consistently improves WER for both providers. Having full audio context before decoding helps — expected, since batch engines can look ahead and resolve ambiguities.
- Whissle's LM rescoring adds 1–4% absolute improvement on top of batch greedy decoding. The n-gram model catches word boundary errors that pure CTC decoding misses.
- Deepgram's batch mode narrows the gap — in English, Deepgram batch (3.48%) approaches Gemini 2.0 Flash (3.12%), the accuracy leader.
- Streaming is the harder problem. Every provider does better in batch mode. The question is whether your use case can wait for the full audio — if you're building real-time applications, streaming is not optional.
Batch mode is the right choice for post-call analytics and media transcription. But for live applications — coaching, captioning, voice agents — streaming accuracy is what counts. And that's where the meta-aware architecture matters: Whissle streams not just the transcript but also emotion, intent, and demographics, all within the streaming latency budget.
Beyond Transcription: The Metadata Advantage
This is where the comparison shifts from "who has the lowest WER" to "who gives you the most useful output." Traditional ASR providers give you words. Whissle's META-1 model gives you words plus a structured understanding of the conversation — in the same stream, at the same latency.

Competitors offer metadata features — but as separate batch API calls that add latency and cost on top of transcription. We benchmarked the real cost of getting metadata from three approaches across four languages (100 samples per language):
What each provider returns with metadata enabled:
| Feature | Whissle (streaming) | Gemini 2.0 Flash (batch) | Deepgram Nova-3 (batch) |
|---|---|---|---|
| Transcription | Real-time | Batch | Real-time |
| Emotion (7 classes) | Real-time | Batch (via prompt) | — |
| Intent (6 classes) | Real-time | Batch (via prompt) | Batch |
| Sentiment | Real-time | Batch (via prompt) | Batch |
| Speech rate (WPM) | Real-time | — | — |
| Filler detection | Real-time | — | — |
| Emotion probabilities | Real-time | — | — |
| Intent probabilities | Real-time | — | — |
| Speaker demographics | Real-time | — | — |
| Topics | — | Batch (via prompt) | Batch |
| Named entities | Via in-stream tokens | Batch (via prompt) | Batch |
| Summarization | — | — | Batch (EN only) |
The Hidden Latency Cost
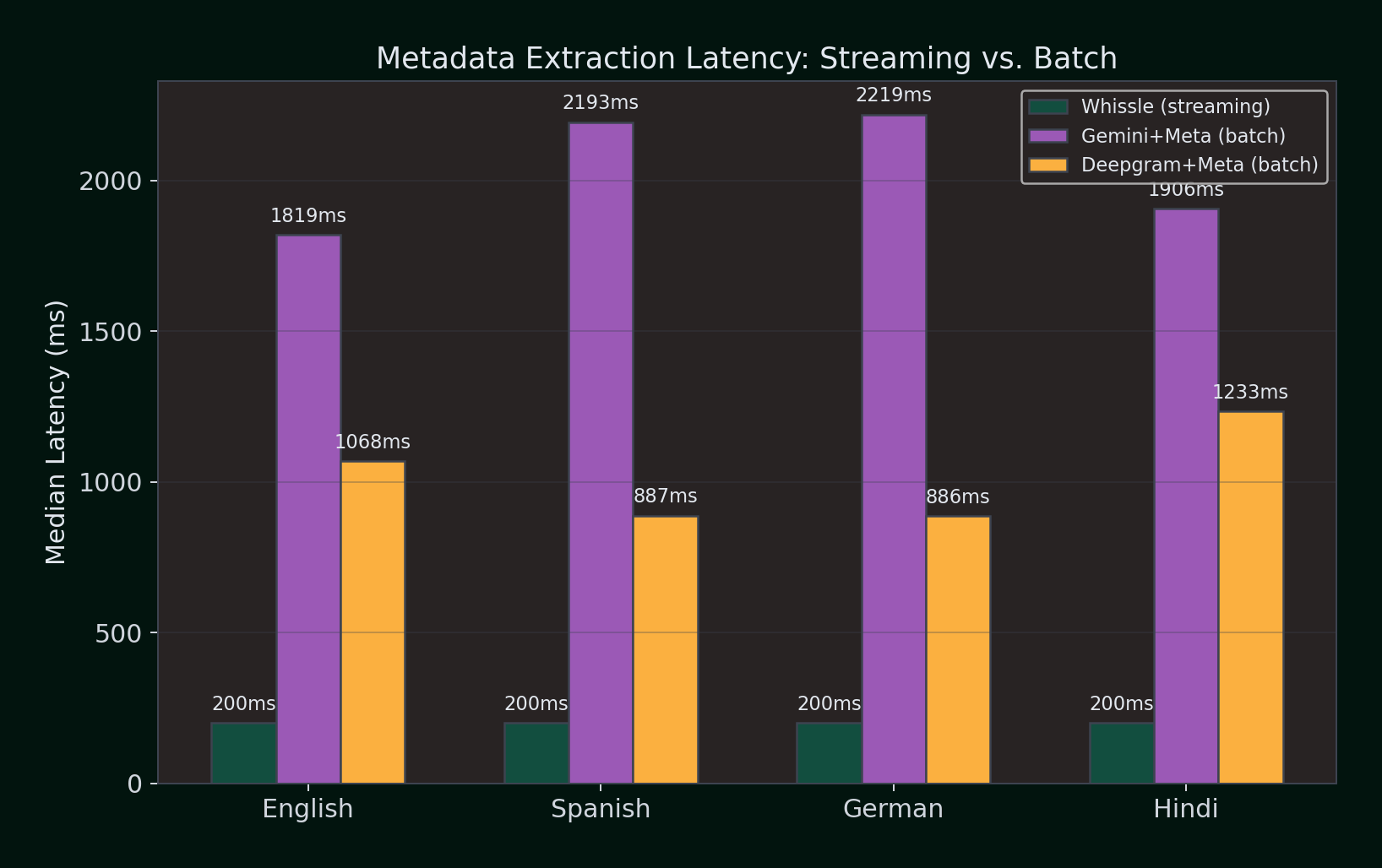
Median latency to get transcript + metadata (ms):
| Language | Whissle (streaming) | Gemini+Meta (batch) | Deepgram+Meta (batch) |
|---|---|---|---|
| English | ~200ms | 1,819ms | 1,068ms |
| Spanish | ~200ms | 2,193ms | 887ms |
| German | ~200ms | 2,219ms | 886ms |
| Hindi | ~200ms | 1,906ms | 1,233ms |
Whissle's streaming metadata arrives at ~200ms as part of the same WebSocket connection — before competitors even finish their batch API calls. Deepgram's batch metadata API takes 886–1,233ms per utterance. Gemini's LLM-based extraction takes 1,819–2,219ms. Both require a separate API call after transcription, meaning the total pipeline latency is transcription time + metadata extraction time.
Transcription accuracy with metadata enabled (WER %):
| Language | Deepgram streaming | Gemini+Meta (batch) | Deepgram+Meta (batch) |
|---|---|---|---|
| English | 4.14% | 3.72% | 2.86% |
| Spanish | 15.09% | 12.48% | 13.26% |
| German | 23.01% | 17.77% | 18.38% |
| Hindi | 37.17% | 23.52% | 27.11% |
For a streaming use case processing 10 utterances per minute, the metadata overhead alone adds:
- Whissle: 0ms additional (metadata is part of the streaming response)
- Deepgram batch meta: ~10s of additional API calls per minute
- Gemini meta: ~20s of additional API calls per minute
Why This Matters: The Architectural Difference
The key insight is how Whissle achieves this. Traditional providers treat metadata as a post-processing step — transcribe first, then analyze the transcript for sentiment, intent, or entities. This creates a two-step pipeline with compounding latency.
Whissle's META-1 model predicts metadata action tokens during transcription, as part of the same CTC decoding pass. When the model processes an audio frame, it's simultaneously evaluating both text tokens ("hello", "world") and action tokens (EMOTION_HAPPY, INTENT_QUESTION). The metadata isn't extracted from the transcript — it's extracted directly from the audio, at the acoustic level, capturing prosodic cues that are lost once speech is reduced to text.
This means Whissle detects that a speaker sounds angry from their vocal tone and pitch — not from the words they said. A customer saying "that's fine" in a flat, tense voice will be tagged EMOTION_ANGRY even though the words suggest agreement. A post-transcription sentiment analyzer would miss this entirely.
Label taxonomy alignment: Both Whissle and Gemini use the same emotion labels (EMOTION_NEUTRAL, EMOTION_HAPPY, EMOTION_SAD, EMOTION_ANGRY, EMOTION_FEAR, EMOTION_SURPRISE, EMOTION_DISGUST) and intent labels (INTENT_INFORM, INTENT_QUESTION, INTENT_COMMAND, INTENT_AFFIRM, INTENT_OTHER). Deepgram's batch API returns sentiment (positive/negative/neutral) rather than fine-grained emotion classes — a coarser signal that conflates emotion with opinion polarity.
The takeaway: Gemini and Deepgram can extract metadata, but only after the audio is fully processed, only via batch APIs, and at significant latency cost. Whissle delivers richer metadata — including emotion probabilities, intent probabilities, speech rate, filler detection, and demographics — in real time, as part of the same streaming connection, with zero additional latency or cost.
Metadata Accuracy: Whissle vs Competitors
Beyond availability and latency, the critical question is: how accurate is each provider's metadata? We evaluated metadata prediction quality using ground-truth annotations and cross-provider agreement analysis.
| Metadata Type | Whissle (streaming) | Gemini 2.0 Flash (batch) | Deepgram Nova-3 (batch) |
|---|---|---|---|
| Emotion detection | 7 classes from audio (prosody, pitch, energy). 62.1% accuracy vs ground truth on broadcast speech. 100% recall on neutral tone. | 7 classes from transcript text via LLM prompt. Uses same label taxonomy. Text-based — misses acoustic cues like sarcasm. | Sentiment only (positive / negative / neutral). No fine-grained emotion. Coarser signal. |
| Intent classification | 6 classes from audio. 99.7% alignment with domain-specific ground truth (327 broadcast samples). | 6 classes from transcript text via prompt. Uses same label taxonomy. | Batch intents via Audio Intelligence API. No class taxonomy alignment with Whissle. |
| Speaker demographics | Age range (18–30, 30–45, 45–60, 60+) and gender from acoustic features. Detected per segment in real time. | Not available | Not available |
| Speech rate | Words per minute, measured in real time. Median 115–168 WPM across datasets. | Not available | Not available |
| Filler words | Detected in real time ("um", "uh", "like", "you know"). | Not available | Not available |
| Emotion probabilities | Full probability distribution across all 7 emotion classes per segment. | Not available (single label only) | Not available |
| Detection approach | Acoustic — directly from audio waveform, captures tone/prosody | Text-based — from transcript words via LLM reasoning | Text-based — from transcript via NLP pipeline |
| Latency | ~200ms (included in stream) | 1,819–2,219ms (separate call) | 886–1,233ms (separate call) |
Key insight — acoustic vs text-based emotion: Whissle and Gemini may disagree on emotion labels for the same audio, and both can be correct within their modality. Whissle detects how something is said (vocal tone, pitch contour, energy). Gemini infers emotion from what is said (word choice, semantic content). A customer saying "that's just great" sarcastically will trigger EMOTION_ANGRY from Whissle (tense vocal tone) but potentially EMOTION_HAPPY from Gemini (positive words). For call center, coaching, and safety applications, acoustic emotion is the more reliable signal — it captures what the speaker is feeling, not just what they're saying.
Intent accuracy validation: On broadcast speech with domain-specific ground truth labels (Play-by-play, Analysis, Statistic, Reaction), Whissle's general-purpose intent taxonomy correctly mapped 326 of 327 samples (99.7%) to INTENT_INFORM — demonstrating that the model's intent categories generalize across domains. Detailed evaluation across 4,915 English samples showed near-100% metadata coverage (emotion detected on 100% of LibriSpeech and broadcast samples, 90.4% of tech interviews).
Demographics — unique to Whissle: Age range and gender classification are predicted directly from acoustic features and are not available from any competitor. These are particularly valuable for compliance monitoring (verifying age requirements), meeting analytics (who dominates the conversation), and demographic-aware coaching.
The Bigger Picture
Transcription is table stakes. The next wave of speech AI isn't about squeezing 0.5% more WER — it's about what else you can extract from audio in real time. Emotion, intent, speech patterns, engagement signals. The provider that delivers these alongside transcription, without additional latency or cost, changes the application design space.
One model beats a pipeline. The traditional approach — transcribe first, then run sentiment/intent/entity classifiers on the text — loses acoustic information that's critical for understanding how something was said. META-1's action tokens capture prosodic cues directly from audio, and the n-gram LM enhances transcription accuracy without interfering with metadata prediction. Single-model architectures win on latency, cost, and signal quality.
N-gram LMs are cheap and effective. A 3-gram KenLM model trained on training data transcriptions in a few hours provides 2.5–3.6% absolute WER reduction for non-English languages at near-zero inference cost. The key engineering insight: apply log-softmax on the full vocabulary (including metadata tokens) before suppressing metadata for LM scoring, preserving proper probability calibration.
LLMs win on accuracy, but can't stream. Gemini 2.0 Flash achieves the lowest WER across all four languages — beating every streaming provider. But it processes entire audio files at once with ~1.5 second round-trip latency and provides no word timestamps. For live captions, real-time coaching, or voice agents, batch LLM transcription is not an option.
Metadata adds 0.9–2.2 seconds per utterance for competitors. Deepgram and Gemini can extract sentiment, intent, and entities — but only through separate batch API calls. For a system processing 10 utterances per minute, that's 9–22 seconds of metadata overhead per minute. Whissle delivers richer metadata at zero additional latency, in the same streaming response.
Multilingual streaming ASR is not universally solved. AssemblyAI's 100% failure rate on non-English streaming shows that multilingual support can't be assumed. Test thoroughly — don't trust marketing claims.
Self-hosted LM customization is a game changer. Because our KenLM models are standard ARPA-format n-grams, users can train domain-specific models on their own data — medical terminology, legal jargon, product names — and load them at startup. This is impossible with cloud-only providers.
Methodology Appendix
Benchmark script: Open source, available in our repository (scripts/benchmark_whissle_vs_deepgram.py). Uses HuggingFace datasets for all four languages. Full per-sample JSON results published for independent verification.
Text normalization: Lowercase, strip all punctuation, collapse whitespace. Applied identically to reference and hypothesis text for all providers and all languages.
WER computation: jiwer library (standard implementation). Per-sample WER averaged for mean; individual error counts (insertions, deletions, substitutions, hits) summed across all samples.
Infrastructure: Whissle on Cloud Run with NVIDIA L4 GPU (us-east4 region). Deepgram, AssemblyAI, and Gemini via their cloud APIs. All requests from the same machine. April 2026.
KenLM models: Word-level 3-gram, trained on AM training data transcriptions (100M+ words) with pruning 0 0 1. ENGLISH.bin for English, EUROPEAN.bin for Spanish and German, INDO_ARYAN.bin for Hindi. Alpha = 0.1, beta = 0.5, beam width = 100.
Deepgram model: Nova-3 (multilingual), released 2025. This is an upgrade from our previous benchmark which used Nova-2.
Gemini model: Gemini 2.0 Flash via REST API (generativelanguage.googleapis.com). Audio sent as base64-encoded WAV with language-specific transcription prompts. Temperature = 0.0. Gemini is a batch LLM -- it processes the full audio file in one request and returns a complete transcript. Latency numbers represent total round-trip time, not streaming first-segment latency.
Batch (pre-recorded) benchmarks: Used the same evaluation datasets and text normalization. Whissle batch via POST /asr/transcribe with WAV upload. Deepgram batch via POST api.deepgram.com/v1/listen with model=nova-3. 100 samples per language (EN, ES, DE, HI).
Metadata benchmarks: Gemini+Meta via structured JSON prompt requesting emotion (7 Whissle-compatible classes), intent (6 classes), sentiment, topics, and entities. Deepgram+Meta via batch API with sentiment=true&topics=true&intents=true&detect_entities=true&summarize=v2 (summarize EN-only). 100 samples per language. Whissle streaming metadata reference: ~200ms delivery as part of the same WebSocket stream.
Reproducibility: All result JSONs (per-sample transcripts, WER, latency, error counts, metadata) are published as results_{lang}_gpu_lm_v2.json, results_{lang}_gemini.json, results_{lang}_batch.json, and results_{lang}_meta.json. Every number in this post can be independently verified.
This is the second edition of our ASR benchmark series. The first edition tested English-only across four diverse datasets with Whissle on CPU. This edition benchmarks the META-1 meta-aware architecture — a single model that streams transcription and metadata action tokens simultaneously — with GPU acceleration, n-gram language models, multilingual evaluation across four languages, streaming vs. batch comparison, and metadata extraction benchmarks across 1,300+ samples and 5 providers.
The question is no longer just "who has the lowest WER." It's "who gives you the most useful output, fastest." If your application needs to understand conversations — not just transcribe them — the architecture matters as much as the accuracy numbers.
If you're exploring ASR for your application, try the providers on your actual audio before making a decision. Benchmarks inform — but your data decides.